 solee
solee
GANimation(1) - 논문 리뷰
안녕하세요!
이번 글은 이미지의 표정을 해부학적으로 의미있고 연속적으로 변환할 수 있어 표정 애니메이션을 만들 수 있어 GANimation이라 불리는 GANimation: Anatomically-aware Facial Animation from a Single Image 논문에 대해 살펴보겠습니다.
소개
Generative Adversarial Network는 발전하며 StarGAN과 같은 구조로 많은 발전이 이루어졌습니다. 나이, 머리색, 성별과 같이 여러 얼굴 속성을 변경할 수 있는 StarGAN은 데이터셋에 정의된 속성으로만 입력 이미지를 변환할 수 있으며 연속적인 변환이 불가능합니다. 예시로 RaFD 데이터셋을 학습했다면 얼굴 표정에 대한 8개의 이진 라벨, 즉 슬픔, 중립, 분노, 경멸, 혐오, 놀람, 두려움, 행복함에 대해 얼굴 표정 변환이 가능하며 다른 표정으로는 변환할 수 없습니다.
GANimation에서는 특정 표정 도메인에 해당하는 데이터셋이 없더라도 다양한 표정으로 변환이 연속적으로 가능하고 고해상도 이미지에도 자연스럽게 모델을 적용할 수 있는 것이 장점입니다. 이와 같은 장점을 가지기 위한 GANimation의 특징 두가지는 Action Units와 Attention Layer입니다.
Action Units
논문에서 얼굴 표정은 얼굴 근육으로 결합되고 조절된 행동의 결과로 하나의 라벨로 정의될 수 없다 언급합니다. 따라서 GANimation에서는 슬픔, 행복함과 같은 정의된 표정 라벨로 얼굴 표정을 변환하는 것이 아니라 해부학적 관점으로 얼굴 표정을 변환하기 위해 Action Units이라 불리는 근육 별 움직임을 사용합니다. Action Units은 Pal Ekman과 Wallace Friesen이 개발한 Facial Action Coding System(FACS)에서 얼굴 근육을 기반으로 얼굴 표정을 분석하기 위해 사용되는 얼굴 근육 동작 단위입니다. Action Units의 수는 많지 않지만 7,000개 이상의 다른 AU 조합이 가능하다고 합니다.
각각 AU에 대한 정보는 FACS-Facial Action Coding System에서 확인할 수 있습니다. 예시로 공포에 대한 표정을 표현하기 위해서는 일반적으로 Inner Brow Raiser(AU1), Outer Brow Raiser(AU2), Brow Lowerer(AU4), Upper Lid Raiser(AU5), Lid Tighttener(AU7), Lip Stretcher(AU20), Jaw Drop(AU26)를 사용하며 각 AU의 크기에 따라 표현하는 공포의 감정 크기가 달라집니다.
GANimation은 StarGAN와 같이 특정 도메인에 해당하는 이미지를 조건화하는 대신 각 action unit의 존재 유무와 크기를 나타내는 1차원 벡터에 조건화되는 GAN 구조를 구축합니다.
Attention Layer

Fig.5. Attention mask $\mathrm{A}$(첫번째 행)와 Color mask $\mathrm{C}$(두번째 행)의 변화 과정.
Attention mask $\mathrm{A}$의 어두운 영역은 이미지의 해당 영역이 각 특정 AU와 더 관련이 있음을 나타냅니다. 원본 이미지에서는 밝은 영역이 유지됩니다.
이전에 다뤘던 모델들과는 다르게 GANimation의 생성 모델은 2개의 이미지를 결과로 출력합니다. 바로 Attention mask와 Color mask입니다. Attention mask $\mathrm{A}$는 AUs에 집중하기 위한 이미지로 표정 변화와 관련된 픽셀들만 추측할 수 있도록 도와주는 mask입니다. 입력 이미지에서 배경에 해당하는 부분은 $\mathrm{A}$에서는 하얀색으로, 표정 변화와 관련이 깊은 픽셀일 수록 검은색에 가까운 색으로 표현됩니다. 배경 픽셀로 판단된 픽셀은 원본 이미지에서 복사해서 가져오는 방식을 사용해 자연스러운 결과 이미지를 생성하는 것이 GANimation의 장점입니다.
Fig.5의 이미지에서 Attention mask 와 Color mask $\mathrm{C}$의 예시를 볼 수 있습니다. 크게 변형되는 얼굴 근육이 검은색에 가까운 색을 띄고 있는 $\mathrm{A}$와 $\mathrm{A}$에서 하얀색으로 표현되어 배경과 관련된 영역이라 판단된 픽셀들은 원본 이미지에서 픽셀 값을 가져오기 때문에 해당 픽셀들은 $\mathrm{C}$에서 사용되지 않습니다. Fig.5의 $\mathrm{C}$의 외곽 부분은 $\mathrm{A}$에서 배경 픽셀인 하얀색에 해당해 사용되지 않기에 색상이 녹색 파란색 널뛰고 있는 $\mathrm{C}$를 볼 수 있습니다.
사용 데이터셋 & 라벨링
GANimation은 데이터셋으로 AU 라벨링이된 얼굴 표정 이미지를 가진 EmotionNet Dataset을 사용했으며 전체 약 100만개의 데이터 중 약 200,0000개를 사용했다 합니다.
이미지 $\mathrm{I}$에 대한 AU 라벨링 값은 $\mathrm{y}$로 표현합니다. 입력 이미지가 $\mathrm{I _{y_r}}$ 일 때 이 이미지의 AU 라벨링 값은 $\mathrm{y_r}$이 됩니다. 모든 표정 표현은 $N$개의 action unit으로 이루어져 있으며 $\mathrm{y_r} = (y_1, \dots, y_N)^{\mathsf{T}}$에 인코딩됩니다. 이때 각 $y_n$은 n번째 action unit의 크기를 0과 1 사이의 정규화된 값을 나타냅니다. 0부터 1 사이의 값으로 표현 덕분에 continuous한 표현이 가능하며 여러 표정 사이 자연스러운 보간이 가능해 사실적이고 부드러운 얼굴 표정을 표현할 수 있습니다.
GANimation의 목표는 action unit $\mathrm{y_r}$에 해당하는 입력 이미지 $\mathrm{I _{y_r}}$을 목표 action unit $\mathrm{y_g}$에 해당하는 결과 이미지 $\mathrm{I _{y_g}}$로 변환할 수 있는 매핑 $\mathcal{M}$을 학습하는 것입니다. 매핑 $\mathcal{M} : (\mathrm{I _{y_r}}, y_g) \rightarrow \mathrm{I _{y_g}} $을 추정하기 위해 목표 action unit $\mathrm{y^m_g}$를 랜덤하게 생성해 사용합니다. 목표 action unit인 $\mathrm{y_g}$를 랜덤으로 생성하기 때문에 입력 이미지의 표정을 변환하기 위해 목표 표현을 가진 페어 이미지 $\mathrm{I _{y_g}}$가 필요하지 않은 비지도 방식을 사용합니다.
모델
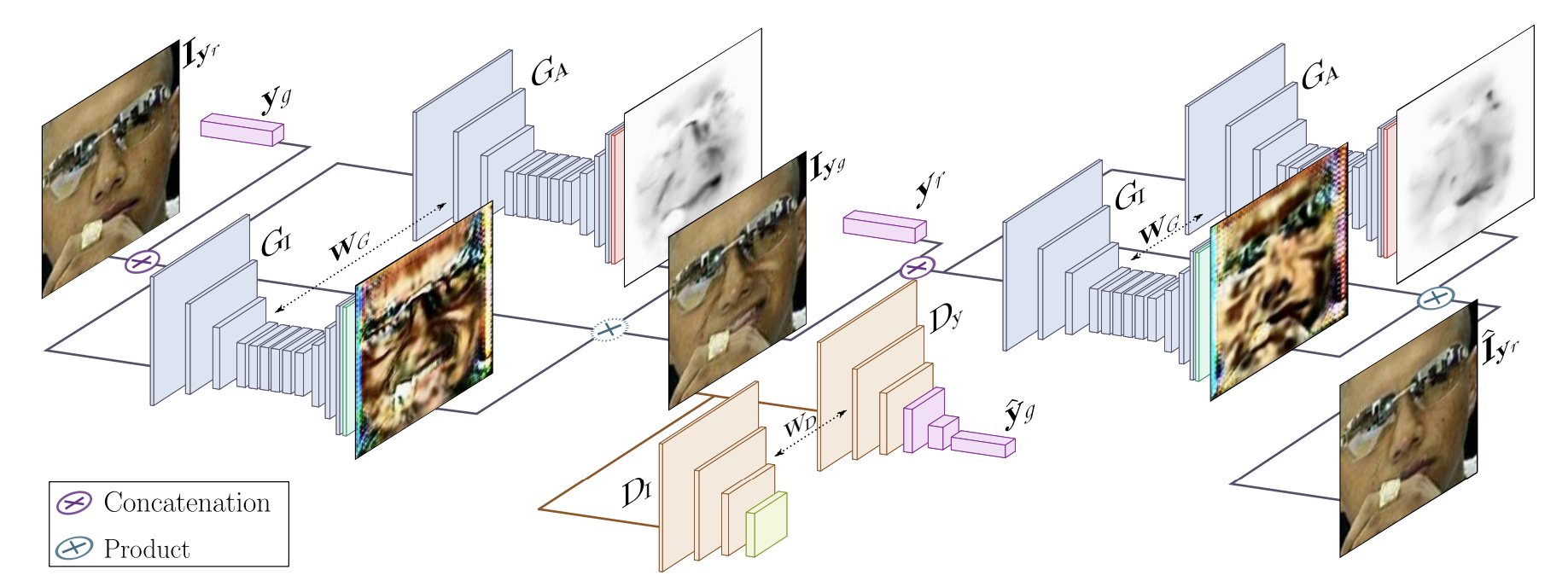
Fig.2. GANimation으로 사실적인 조건부 이미지를 생성하는 방법의 개요.
제안된 구조는 2개의 메인 블록으로 이루어져 있습니다. Color mask와 Attention mask를 생성하는 모델 $G$와 생성된 이미지가 사실적인지 판별하는 $D_I$와 조건에 충족하는 표현 $\hat{y_g}$에 대해 평가하는 판별 모델 $D$가 있습니다.
이 방법은 지도 학습이 필요하지 않습니다. 즉, 표현이 다른 동일한 사람에 대한 이미지페어나 목표 이미지 $\mathrm{I _{y_g}}$가 필요하지 않습니다.
Fig.2는 GANimation의 이미지 생성에 대한 개요를 보여줍니다. GANimation은 2개의 주요 모듈로 구성되어 사실적인 조건부 이미지를 생성하는 새로운 접근 방식을 제안합니다.
첫번째 주요 모듈은 bidirectional adversarial architecture입니다. 표정 $\mathrm{y_r}$을 가지고 있는 입력 이미지 $\mathrm{I _{y_r}}$을 목표 조건 $\mathrm{y_g}$에 해당하는 이미지로 변환한 이미지 $\mathrm{I _{y_g}}$를 생성 모델로 생성합니다. 판별 모델은 $\mathrm{I _{y_g}}$가 진짜 이미지인지 아닌지 판별하고 이미지의 표정을 분석해 $\hat{\mathrm{y}} _{\mathrm{g}}$를 얻어 이미지를 생성할 때 사용한 $\mathrm{y_g}$와의 차이를 계산해 loss에 사용합니다.
이후 생성 모델은 초기 이미지의 표정이였던 $\mathrm{y_r}$을 다시 $\mathrm{I _{y_g}}$에 적용해 원본과 유사한 이미지 $\hat{\mathrm{I}} _{\mathrm{y_r}}$을 생성합니다. 생성된 $\hat{\mathrm{I}} _{\mathrm{y_r}}$와 원본 이미지 $\mathrm{I _{y_r}}$과의 차이를 loss에 사용합니다. bidirectional은 생성 모델이 2번 적용되는 $\mathrm{I _{y_r}} \rightarrow G(\mathrm{I _{y_r}} | \mathrm{y_g}) \rightarrow G(G(\mathrm{I _{y_r}} | \mathrm{y_g}) | \mathrm{y_r}) = \hat{\mathrm{I}} _{\mathrm{y_r}}$ 과정을 의미합니다.
두번째 주요 모듈은 attention layer입니다. 입력 이미지에서 변화하는 배경과 다양한 조명 조건을 처리할 수 있도록 표정과 관련된 영역만 처리하는 것에 초점을 맞추는 attention mechanism을 사용합니다. Fig.2에서 ${\mathrm{G_A}}$로 표시되는 이미지들이 attention mask로 표정과 관련된 픽셀일 수록 검은색으로 표현되는 것을 볼 수 있습니다.
생성 모델 $G$, 판별 모델(Critic) $D$를 순서대로 조금 더 자세하게 살펴보겠습니다!
Generator
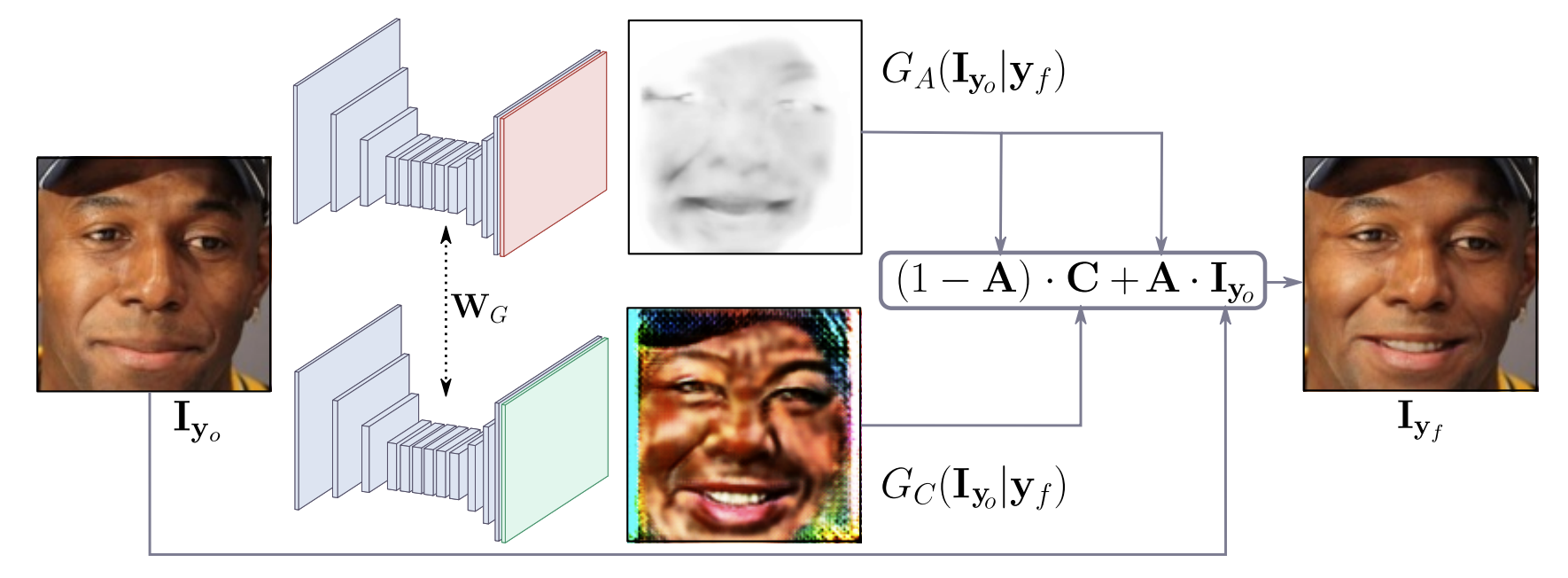
Fig.3. Attention-based generator.
입력 이미지와 목표 표현이 주어지면 생성 모델은 전체 이미지에서 attention mask $A$와 RGB color transformation $C$를 생성합니다. attention mask는 최종 렌더링된 이미지에서 원본 이미지에 각 픽셀들이 어느 정도 확장되는 지를 지정하는 강도를 정의합니다.
생성 모델의 핵심요소는 새로운 표정을 합성하는 이미지의 영역에만 초점을 맞추고 머리, 안경, 모자, 악세사리와 같은 이미지의 나머지 요소를 건드리지 않도록 하는 것입니다. 이를 위해 생성 모델에서는 Attention mechanism을 사용합니다. 생성모델은 color mask C와 attention mask A, 2가지 마스크를 출력하며 Fig.3에서 생성 과정을 볼 수 있습니다.
Color mask $C$는 입력 이미지 $\mathrm{I _{y_o}}$와 조건부에 해당하는 action unit 라벨 $\mathrm{y_f}$을 입력받아 $\mathrm{y_f}$에 해당하는 RGB 이미지 $G_C(\mathrm{I _{y_o}} | \mathrm{y_f})$를 만든 것으로 RGB color 이미지이므로 $C = G_C(\mathrm{I _{y_o}} | \mathrm{y_f}) \in \mathbb{R}^{H \times W \times 3}$입니다.
Attention mask $A$는 입력 이미지 $\mathrm{I _{y_o}}$와 조건부에 해당하는 action unit 라벨 $\mathrm{y_f}$을 입력받아 흑백 이미지(gray scale) 이미지 $G_A (\mathrm{I _{y_o}} | \mathrm{y_f})$를 만든 것으로 흑백 이미지이고 [0, 1] 범위 안에서 표현되기 때문에 $A = G_A(\mathrm{I _{y_o}} | \mathrm{y_f}) \in \lbrace 0, \dots ,1 \rbrace ^{H \times W}$입니다.
$A$는 $C$의 각 픽셀들이 변형되고 확장되는 정도를 나타냅니다. 얼굴 움직임을 정의하고 변형되어야 하는 픽셀들은 0에 가까운 검은 색으로, 변형되지 않은 픽셀들은 1에 가까운 하얀색으로 표현됩니다. 변형되지 않아도 되는 하얀 픽셀들은 원본 이미지 $\mathrm{I _{y_o}}$ 에서 픽셀 값을 가져오고 변형되어야 하는 검은 픽셀들은 Color mask $C$에서 가져옵니다.
\[\mathrm{I _{y_f}} = (1-A) \cdot C + A \cdot \mathrm{I _{y_o}}\]위의 식을 사용해 Attention mask $A$, Color mask $C$, 원본 이미지 $\mathrm{I _{y_o}}$를 합성한 최종 이미지 $\mathrm{I _{y_f}}$를 계산할 수 있습니다. 만약 $A$의 ($i$, $j$) 위치 픽셀 $A _{ij}$의 값이 0.3이고 원본 이미지의 해당 위치 픽셀 $\mathrm{I _{ij}}$값이 (100, 150, 100)이고 $C$의 해당 위치 픽 $C _{ij}$의 값이 (200, 250, 200)이라면 최종 이미지 $(i,j)$ 위치의 값은 $(1-A) \cdot C + A \cdot I$로 계산해 (170, 220, 170)이 됩니다.
Condition Critic
StarGAN과 마찬가지로 WGAN-GP 기반 판별 모델 $D$를 사용해 생성된 이미지($\mathrm{I _{y_g}}$)의 품질과 표현을 평가합니다.
$D(\mathrm{I})$의 구조는 입력 이미지 $\mathrm{I}$의 행렬 $\mathrm{Y_I} \in \mathbb{R} ^{H / 2^6 \times W/2^6}$에 매핑하는 pix2pix에서 사용한 PatchGAN과 유사하며, 여기서 $\mathrm{Y_I}[i, j]$는 patch $ij$가 실제 데이터일 확률을 나타냅니다.
추가로 판별 모델은 입력된 이미지가 실제 이미지인지 가짜 이미지인지에 대한 판별 외에도 이미지의 condition, 즉 조건에 대해서도 판별을 합니다. StarGAN의 Domain classification처럼 이미지가 어떤 condition을 가지고 있는지 판별모델이 측정합니다. StarGAN에서는 어떤 도메인에 속하는지를 계산했었다면 GANimation에서는 실제 이미지를 학습할 때 실제 이미지가 어떤 AUs가 활성화되어있는지 $\hat{\mathrm{y}} = (\hat{y}_1, \dots, \hat{y}_N)^T$를 계산합니다.
안정성을 향상시키기 위해 SimGAN에서 제안한 것처럼 생성 모델의 업데이트에서 생성된 이미지 버퍼를 사용해 판별 모델을 업데이트하려고 시도했지만 성능 향상을 관찰하지 못했다고 합니다.
Loss
Loss는 총 4가지가 있습니다. 생성된 이미지의 분포를 학습 데이터 이미지 분포로 변화시키는 adversarial loss, attention mask를 매끄럽게 하기 위한 attention loss, 생성된 이미지들의 조건부인 AU를 표현하도록 하는 Conditional expression loss, 사람의 identity를 유지하기 위한 Identity loss가 있습니다.
Image Adversarial Loss
생성 모델을 학습하기 위해 WGAN-GP가 제안한 알고리즘을 사용합니다. 이전 글인 StarGAN(1)글의 adversarial loss와 같네요.
기존 GAN은 Jenson-Shannon(JS) divergence loss를 기반으로 생성 모델이 판별 모델을 속이고, 판별 모델은 실제 이미지와 생성 이미지를 올바르게 분류할 확률을 최대화하는 것을 목표로 합니다. 기존 GAN loss는 잠재적으로 생성 모델 파라미터들이 연속적이지 않으며 일부 포화상태가 되어 gradient vanishing이 발생할 수 있어 WGAN에서 JS를 연속적인 Earth Mover Distance로 대체해 해결합니다. 이후 Lipschitz 제약 조건을 만족하기 위해 WGAN-GP는 판별 모델에 gradient norm으로 계산된 gradient penalty를 추가한 알고리즘을 만들었으며 GANimation에서 WGAN-GP의 알고리즘을 사용합니다.
GANimation에서 사용하는 critic loss $\mathcal{L} _I(G, D _\mathrm{I}, \mathrm{I _{y_o}}, \mathrm{y_f})$는 아래와 같습니다.
\[\mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}} [D _\mathrm{I}(G(\mathrm{I _{y_o}} | \mathrm{y_f}))] - \mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}}[D _\mathrm{I(I _{y_o})}] + \lambda _{gp}\mathbb{E} _{\tilde{I} \sim \mathbb{P} _{\tilde{I}}}[(\| \nabla _{\tilde{I}} D_I(\tilde{I})\| -1 )^2]\]$\mathrm{I _{y_o}}$는 원본 이미지 조건(condition) $\mathrm{y_o}$와 있는 입력 이미지, $\mathrm{y_f}$는 목표 조건, $\mathbb{P} _{\mathrm{o}}$는 입력 이미지의 데이터 분포, $\mathbb{P} _{\tilde{I}}$는 무작위 보간 분포(random interpolation distribution)입니다. $\lambda _{gp}$는 panalty 계수입니다.
Attention Loss
Attention loss는 원본 이미지에서 자연스러운 변환을 위해 사용하는 Attention mask $A$을 사용한 loss입니다. 입력 이미지의 픽셀과 color transformation C를 결합할 때, 원활한 색 변환을 수행하기 위해 A에 대한 Total Variation regularization $\sum^{H, W} _{i, j}[(A _{i+1, j} - A _{i,j})^2 + (A _{i, j+1} - A _{i, j})^2]$ 을 수행합니다. TV loss라고도 불리는 Total Variation은 생성한 이미지의 픽셀들을 부드럽게 처리하고 노이즈를 줄일 수 있는 방법으로 인접하고 있는 픽셀 간의 차이를 계산해 loss로 사용합니다.
모델을 학습할 때 Attetion mask $A$는 Color mask $C$와 마찬가지로 Critic의 결과에 따라 gradients와 loss로부터 학습됩니다. 그러나 $C$의 출력 범위는 [0, 255] 인 것에 비해 $A$는 [0, 1]로 범위가 좁아 생성모델 $G$의 몇몇 weight 값들이 커지면 쉽게 1로 포화될 수 있어 L2-wight penalty로 regularize합니다. L2를 $A$에 적용한 수식 $\mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}}[\parallel A \parallel _2]$을 Attention loss에 추가합니다.
Attention loss $\lambda _A(G, \mathrm{I _{y_o}}, \mathrm{y_f})$은 아래와 같이 정의됩니다.
\[\lambda _{TV} \mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}} \left[ \sum^{H, W} _{i, j}[(A _{i+1, j} - A _{i,j})^2 + (A _{i, j+1} - A _{i, j})^2] \right] + \mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}}[\| A \|_2]\]$A=G_A(I_{y_o}|y_f)$와 $A_{i, j}$의 $i$, $j$의 entry이고 $\lambda _{TV}$는 penalty 계수입니다.
Conditional Expression Loss
생성 모델은 image adversarial loss를 줄이는 동시에 판별모델이 이미지 조건인 AUs를 측정하는 Condition Critic의 오류 또한 줄여야 합니다. 이를 통해 $G$는 현실적인 결과를 렌더링하는 것을 학습할 뿐만 아니라 생성된 이미지가 조건 $\mathrm{y_f}$에 의해 만들어진 목표 얼굴 표정을 만족하도록 학습합니다.
Conditional Expression Loss $\mathcal{L} _Y(G, D_Y, \mathrm{I _{y_o}}, \mathrm{y_o}, \mathrm{y_f})$는 아래와 같이 계산됩니다.
\[\mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _\mathrm{o}} [\| D _{\mathrm{y}}(G(\mathrm{I _{y_o}} | \mathrm{y_f})) - \mathrm{y_f} \| ^2 _2] + \mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}} [\| D _\mathrm{y}(\mathrm{I _{y_o}}) - \mathrm{y_o} \| ^2 _2]\]Conditional Expression Loss 수식은 $D$에게 $G$가 생성한 가짜 이미지를 사용한 경우와 진짜 이미지를 사용한 경우, 2가지 경우로 나뉩니다.
$D$에게 $G$가 생성한 가짜 이미지를 사용한 경우 $G$가 입력 이미지 $\mathrm{I _{y_o}}$에 조건 $\mathrm{y_f}$을 합성한 $G(\mathrm{I _{y_o}} | \mathrm{y_f})$를 판별 모델이 입력으로 받아 이미지가 표현한 action units에 대한 값을 계산한 $D _{\mathrm{y}}(G(\mathrm{I _{y_o}} | \mathrm{y_f}))$와 조건 $\mathrm{y_f}$와의 차이를 계산합니다.
$D$에게 진짜 이미지를 사용한 경우 입력 이미지 $\mathrm{I _{y_o}}$를 판별 모델이 입력으로 받아 이미지가 표현한 action units에 대한 값을 계산한 $D _{\mathrm{y}}(\mathrm{I _{y_o}})$와 입력 이미지의 action units 값인 $\mathrm{y_o}$와의 차이를 계산합니다.
Identity Loss
Adversarial loss, Attention loss, Conditional expression loss는 생성 모델이 사진처럼 사실적이고 조건인 AUs에 맞는 사진을 생성하도록 하기 위한 loss라면 Identity loss는 생성된 이미지의 사람이 원본 이미지와 동일한 사람이도록 얼굴 identity, 사람 얼굴 정체성을 유지하기 위한 loss입니다.
CycleGAN의 cycle consistency loss을 사용해 원본 이미지 $\mathrm{I _{y_o}}$와 reconstruction 이미지 간의 차이에 페널티를 주어 생성 모델이 각 개인의 정체성을 유지하도록 합니다.
\[\mathcal{L} _{idt}(G, \mathrm{I _{y_o}}, \mathrm{y_o}, \mathrm{y_f}) = \mathbb{E} _{\mathrm{I _{y_o}} \sim \mathbb{P} _{\mathrm{o}}}[\| G(G(\mathrm{I _{y_o}} | \mathrm{y_f}) | \mathrm{y_o}) - \mathrm{I _{y_o}} \|_1]\]L1-norm을 perceptual loss로 대체하는 것을 시도했으나 향상된 성능을 관찰하지는 못했다고 합니다.
Full Loss
목표 이미지 $\mathrm{I _{y_g}}$를 생성하기 위해 위의 loss를 선형적으로 결합해 손실 함수 $\mathcal{L}$을 계산합니다.
\[\displaylines{ \mathcal{L} = \mathcal{L} _{\mathrm{I}}(G, D _{\mathrm{I}}, \mathrm{I _{y_r}}, \mathrm{y_g}) + \lambda _{\mathrm{y}} \mathcal{L} _{\mathrm{y}} (G, D _{\mathrm{y}}, \mathrm{I _{y_r}}, \mathrm{y_r}, \mathrm{y_g}) \\ + \lambda _{\mathrm{A}}(\mathcal{L} _{\mathrm{A}}(G, \mathrm{I _{y_g}}, \mathrm{y_r}) + \mathcal{L _{\mathrm{A}}}(G, \mathrm{I _{y_r}}, \mathrm{y_g})) + \lambda _{\mathrm{idt}} \mathcal{L} _{\mathrm{idt}}(G, \mathrm{I _{y_r}}, \mathrm{y_r}, \mathrm{y_g}) }\]$\lambda_A, \lambda_y, \lambda_{idt}$는 hyper-parameter로 모든 loss term의 상대적 중요도를 조절합니다.
결과
결과에서는 단일 Action Unit 조절, 다중 Action Units 조절을 연속적으로 테스트한 결과, 베이스 라인 모델들과 표정 변화를 불연속적으로 테스트해 비교한 결과, wild 이미지 결과 그리고 모델의 한계와 실패 사례에 대해 보여줍니다.
GANimation은 고해상도 이미지를 처리하기 위해 얼굴을 crop한 이미지 데이터셋을 만들지 않아도 되기 때문에 일부 실험의 고해상도 이미지를 처리하기 위해 이미지 내의 얼굴 부분을 crop하지 않았다고 합니다. 논문에서는 detector(face detector from https://github.com/ageitgey/face_recognition)를 사용해 얼굴 부분을 잘라내고, GANimation로 표정 변환을 적용한 후 생성된 얼굴을 영상의 워낼 위치로 다시 배치했습니다. Attention mechanism은 crop한 얼굴과 원본 이미지 간의 원활한 변환을 보장하기에 다른 모델들에 비해 고해상도 이미지를 처리할 수 있다고 합니다.
Action Units Edition
우선 단일 Action Unit 조절 결과를 보시죠!

Fig.4. Single AUs Edution.
특정 AU는 강도 레벨이 증가할 때 활성화됩니다. 첫번째 행은 모든 경우에 원본 영상을 생성하는 AU 강도 0을 적용한 것에 해당합니다.
사람의 identity를 유지하면서 다양한 강도의 AU를 활성화하는 모델의 능력을 평가했으며 Figure 4는 4단계의 강도(0, 0.33, 0.66, 1)로 변환된 9개의 AU 집합을 보여줍니다.
강도가 0인 경우 AU 근육은 변하지 않으며 0이 아닌 경우 각 AU가 점진적으로 강조되는 것을 관찰할 수 있습니다. 대부분의 경우 실제 이미지와 구별하기 어려운 복잡한 얼굴 움직임을 그럴싸 하게 렌더링함을 볼 수 있습니다. 또한 얼굴 근육 집합의 독립성이 생성 모델에 의해 학습되었는데, 눈과 얼굴의 절반 위 부분에 상대적인 AU(AU 1, 2, 4, 5, 45)는 입의 근육에 영향을 주지 않습니다. 마찬가지로 구강 관련 변형(AU 10, 12, 15, 25)는 눈이나 눈썹 근육에 영향을 주지 않습니다.

Fig.1. 단일 이미지에서 얼굴 애니메이션.
불연속적인 수의 표현에 제한되지 않고 주어진 이미지를 연속적으로 새로운 표현으로 렌더링할 수 있는 해부학적으로 일관된 접근 방식을 제안합니다. 예시에서 가장 왼쪽에 있는 입력 이미지 $\mathrm{I _{y_r}}$(녹색 사각형으로 강조됨)만 제공하며, 매개 변수 $\alpha$는 미소와 같은 표정과 관련된 action unit의 활성화 정도를 제어합니다. 또한 이 시스템은 맨 아래 행의 예시와 같이 비정상적인 조명 조건을 가진 이미지를 처리할 수 있습니다.
다음은 다중 Action Units 조절 결과입니다. 첫번째 열은 표정 $\mathrm{y_r}$을 가진 원본 이미지이고 가장 오른쪽 열은 목표 표정 $\mathrm{y_g}$를 조건으로 합성된 생성 이미지 결과입니다. 나머지 열은 기존 표정과 목표 표정의 선형 보간($\alpha \mathrm{y_g} + (1-\alpha) \mathrm{y_r}$)으로 조건화된 생성 모델의 결과입니다.
프레임 별 일관된 변환이 매끄럽고 원활하다는 것을 볼 수 있으며 다양한 조명 조건에서도 좋은 결과를 보여주었음은 물론이고 아바타(영화) 이미지의 경우 CG 이미지인만큼 현실이 아닌 비현실 데이터 분포임에도 불구하고 좋은 결과를 보여주었습니다.
With Baseline
다음으로는 여러 baseline 모델들과 비교합니다. DIAT, CycleGAN, IcGAN, StarGAN가 baseline 모델들이고 RaFD 데이터 셋에서 불연속적인 감정 범주(예: 행복, 슬픔, 두려움)를 렌더링합니다. DIAT, CycleGAN은 condition GAN이 아니라 조건화를 허용하지 않기 때문에 가능한 모든 source/target 감정 쌍에 대해 독립적으로 학습한 결과를 사용합니다.

Fig.6. State-of-the-art 와의 질적 비교.
DIAT, CycleGAN, IcGAN, StarGAN, GANimation(Ours)을 사용한 얼굴 표정 합성의 결과들로 입력 이미지와 7가지 다른 얼굴 표정을 나타냅니다. 그림에서 볼 수 있듯이, GANimation(Ours)는 시각적 정확도와 공간 해상도 사이의 최상의 균형을 만듭니다. 현재 최고의 접근 방식인 StarGAN은 결과 중 일부 흐린 부분을 보여줍니다.
논문에서 GANimation은 2가지 주요 측면에서 baseline 모델들의 접근 방식과는 차이가 있다고 언급합니다. 첫번째로 GANimation은 별개의 감정 카테고리를 만들어 모델을 조건화하지 않지만 표현을 연속적으로 생성할 수 있도록 학습합니다.
두번째로 attention mask를 사용해 crop된 얼굴 부분에 적용할 수 있으며 어떤 artifact도 생성하지 않고 기존 이미지에 다시 적용하는 것이 가능합니다. Fig.6 에서 볼 수 있듯이, GAnimation은 다른 접근법보다 시각적으로 더 매력적인 이미지를 생성할 뿐만 아니라 더 높은 공간 해상도의 이미지를 생성합니다.
High expression

Fig.7. 얼굴 표정 분포 공간에서 샘플링한 결과들.
벡터 $\mathrm{y_g}$를 통해 여러 AU를 적용한 결과 동일한 소스 이미지 $\mathrm{I _{y_r}}$에서 다양한 현실적인 이미지를 합성할 수 있습니다.
GANimation은 입력 이미지의 인물 정체성을 보존하면서 해부학적으로 그럴듯하게 광범위한 표정으로 변환한 이미지를 생성합니다. Fig.7 에서 모든 얼굴들은 14 AUs 만으로 정의된 얼굴 구성으로 왼쪽 상단 모서리 입력 이미지를 조정한 결과들입니다. 14 AUs로만 합성할 수 있는 해부학적으로 그럴듯 한 표정의 큰 변동성을 볼 수 있습니다.
Wild image

Fig.8. Wild 이미지에 대한 정성적 평가.
상단 : 영화 “캐리비안의 해적”의 이미지(왼쪽)과 GANimation 방식으로 생성한 생성 이미지(오른쪽)을 나타냅니다.
하단 : 비슷한 방식으로 “왕좌의 게임” 시리즈의 이미지 프레임(왼쪽)을 사용해 표현이 다른 5개의 새로운 이미지를 합성했습니다.
Fig. 5에서 봤던 것처럼 attention mechanism은 얼굴의 특정 부분에 초점을 맞추는 것을 학습할 뿐만 아니라 원본 이미지 배경과 생성된 이미지 배경을 융합할 수 있습니다. Attention에서 설명했던 3단계를 통해 GANimation은 고해상도 이미지를 유지하면서 wild 이미지에 쉽게 적용할 수 있습니다.
- face detector를 이용해 얼굴 부분을 잘라낸다.
- GANimation으로 잘라낸 얼굴 이미지에 표정 변환을 적용한다.
- 생성된 얼굴을 영상의 원래 위치에 배치한다.
Fig.8은 Wild 이미지에 GANimation을 적용한 2가지 예시를 보여줍니다. Attetion mask를 사용해 전체 프레임과 생성된 얼굴 간에 눈에 띄는 곳 없이 부드러운 병합이 가능합니다.
Limits
마지막으로 모델의 성공, 실패 사례들과 함께 GANimation의 한계에 대한 결과를 살펴봅시다!

Fig.9. 성공 그리고 실패 사례들.
모든 경우에서 소스 이미지는 $\mathrm{I _{y_r}}$, 목표 이미지는 $\mathrm{I _{y_g}}$, color mask와 attention mask는 $C$와 $A$로 각각 표시합니다.
상단 : 극단적인 이미지에서의 몇가지 성공 사례들
하단 : 몇가지 실패 사례들
검은 점선의 위는 성공 사례, 아래는 실패 사례를 의미합니다.
성공 사례부터 살펴보겠습니다. 가장 윗 행의 2개의 예시는 인간처럼 생긴 조각과 비현실적인 그림에 GANimation을 적용한 모습을 보여줍니다. 두 경우 모두 원본 이미지의 예술적인 효과를 유지한 채로 표정이 변한것을 볼 수 있습니다. 또한 Attention mask가 안경과 같은 픽셀들에 가려진 것 같은 아티팩트들을 무시하는 방법을 사용함이 인상적입니다.
2행의 왼쪽 예시는 얼굴 중간에 갈라지는 선처럼 보이는 텍스처가 들어가 있으며 왼쪽 얼굴과 오른쪽 얼굴의 특징이 다릅니다. GANimation은 턱수염이 있는 왼쪽 얼굴과 턱수염이 없는 오른쪽 얼굴 모두에 같은 표정을 적용해 성공적으로 변형함을 볼 수 있습니다.
3행의 오른쪽 예시는 얼굴 스케치 이미지로 생성한 이미지에는 일부 아티팩트를 볼 수 있지만 성공적으로 표정이 변했으며 그림의 질감을 유지한 채 이미지가 생성되었음을 볼 수 있습니다.
다음은 실패 사례입니다. 4행의 오른쪽 사진처럼 안대를 착용해 얼굴의 속성이 일부 누락된 경우 아티팩트를 유발함을 볼 수 있습니다. 마지막 행은 인간이 아닌 경우에 대한 테스트 결과로 왼쪽 사이클롭스 이미지와 오른쪽 사자 이미지에 모델을 적용한 결과 사람 얼굴 특징과 같은 아티팩트들을 발견했습니다.
논문에서 Fig.9의 실패 사례는 모두 학습 데이터가 부족하기 때문이라고 추측합니다.
GANimation 논문 리뷰는 여기서 끝입니다!
해부학적 접근이 특이해서 시작한 GANimation이였는데 Attention mask, Color mask 분리 또한 인상이 깊었습니다. 재미있어요…! ![]()
논문 구현 결과가 조금 기대됩니다. 히히히
이번 글도 끝까지 봐주셔서 감사합니다. 다음 글인 GANimation 코드 구현에서 뵙겠습니다 :)