 solee
solee
StarGAN(1) - 논문 리뷰
이번 논문은 StarGAN입니다!
이전까지 논문 리뷰는 논문 번역을 하고 중요한 내용이나 수식 부분을 제 나름대로 정리한 걸 추가한 방식이였다면 이번 글부터는 논문 자체를 번역하기보다는 전체적인 내용을 요약하고 중요한 부분을 설명하는 방식으로 바꿔볼까 합니다.
그럼 시작하겠습니다![]()
소개

Figure 1. RaFD 데이터셋에서 학습한 지식을 CelebA 데이터셋에 적용한 다중 도메인 이미지 간 변환 결과.
Multi-domain image-to-image 변환 모델인 StarGAN입니다. 이전까지 포스팅했던 생성 모델 논문들은 2개의 도메인을 사용했었고 그 사이만 변환이 가능했었습니다. 따라서 또 다른 도메인으로 이미지를 변환하기 위해서는 다시 모델을 학습해야 했습니다. 이런 한계를 극복하기 위해 StarGAN은 여러 데이터셋을 사용해 다중 도메인 변환이 가능한 것이 특징으로 위의 Fig1 과 같이 RaFD에 있던 표정에 대한 라벨을 CelebA 데이터셋에 적용한 것이 가능합니다.
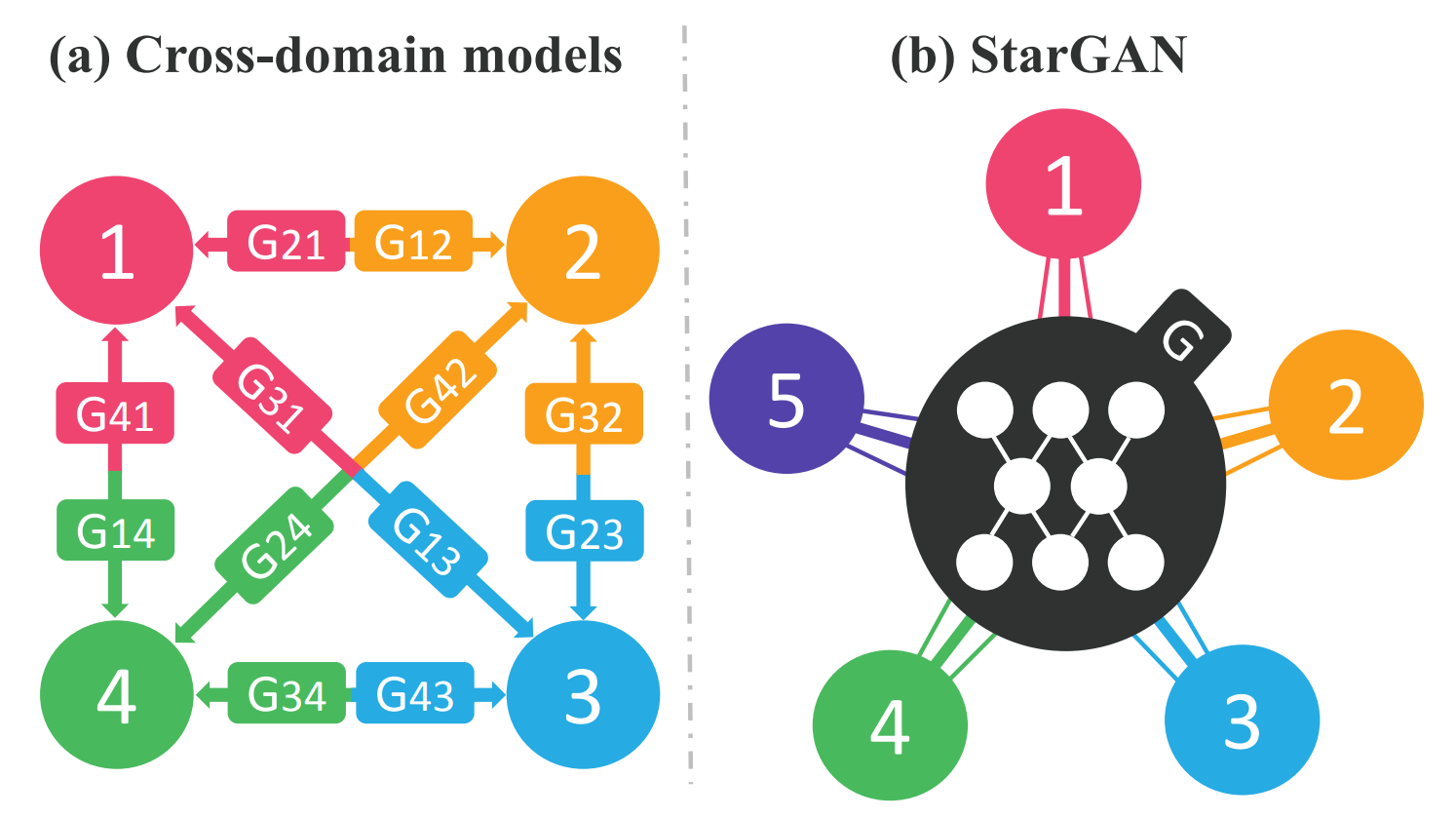
Figure 2. Cross-domain 모델과 우리가 제안한 starGAN의 비교. (a)여러 도메인을 처리하기 위해 모든 이미지 도메인 페어에 대해 Cross-domain 모델을 구축해야 합니다. (b) StarGAN은 단일 생성 모델을 사용해 여러 도메인 간의 매핑을 학습할 수 있습니다. 그림은 여러 도메인을 연결하는 별 모양의 토폴로지를 나타냅니다.
기존 모델들은 $k$ 도메인 간의 변환을 위해서는 $k(k-1)$ 개의 생성 모델을 학습해야 합니다. 얼굴에 대한 도메인만을 사용한다면 얼굴 모양과 같은 모든 도메인의 이미지에서 학습할 수 있는 global features가 존재함에도 불구하고 각 생성 모델은 해당하는 2개의 도메인 데이터에 대해서만 학습해야 하므로 전체 학습 데이터를 완전히 활용할 수 없어 효율적이지 않고 효과적이지 못합니다.
StarGAN은 Fig2에서 볼 수 있듯이 단일 생성 모델만으로 여러 도메인 간의 매핑을 학습할 수 있습니다. 생성 모델은 원본 이미지와 도메인 정보를 활용하는데 도메인 정보를 모델에 넘겨주기 위해 라벨를 사용합니다. 라벨은 binary 또는 one-hot vector 형태로 모델이 입력 이미지를 원하는 목표 도메인으로 유연하게 변하는 것을 학습하도록 도와줍니다.
데이터셋이 하나가 아닌 여러 개를 사용할 경우 라벨에 mask vector(마스크 벡터)를 추가해 사용합니다. 사용하는 데이터셋의 라벨만 확인해 명시적으로 제공하는 라벨에만 집중할 수 있도록 어떤 데이터셋을 사용하는지 모델에 알려주는 역할을 합니다.
사용 데이터셋
StarGAN에서 사용한 데이터셋은 2개로 CelebA와 RaFD가 있습니다. 위의 Figure 1에서 좌측에 해당하는 머리색, 성별, 나이, 피부색은 CelebA 데이터셋에서 나온 라벨이고 우측의 표정에 관한 라벨은 RaFD에 속해있습니다.
CelebA
The CelebFaces Attributes dataset(CelebA)에는 40개의 이진 속성으로 라벨리 달인 유명인의 202,599장 얼굴 이미지가 포함되어 있습니다. 논문에서는 178x218 크기의 원본 이미지를 178x178 크기로 crop한 후 128x128 크기로 resize합니다. 무작위로 2,000개의 이미지를 테스트 데이터으로 선택하고 나머지 모든 이미지를 학습 데이터로 사용합니다. 40개의 속성 중 머리색(검정색, 금색, 갈색), 성별(남, 여), 나이(젊음, 늚음) 속성을 사용해 7개의 도메인으로 구성합니다.
RaFD
The Radboud Faces Database(RaFD)에는 67명의 참가자로부터 수집한 4,824개의 이미지로 구성되어 있습니다. 각 참가자는 세 가지 다른 방향에서 8가지 표정을 짓고 5개의 카메라 각도에서 촬영합니다. 8가지 표정은 분노, 혐호, 공포, 행복, 슬픔, 놀람, 경멸, 중립입니다. 논문에서는 얼굴이 중앙에 위치하도록 256x256 크기로 이미지를 crop한 후 128x128 크기로 이미지를 resize 합니다.
단일 데이터셋 학습
CelebA에서 검은색 머리, 금색 머리, 갈색 머리, 성별 남, 성별 여, 나이 젊음, 나이 늙음 속성으로 총 7개의 도메인을 사용합니다. 우선 단일 데이터셋에서 다중 도메인을 사용하는 경우를 살펴봅시다!
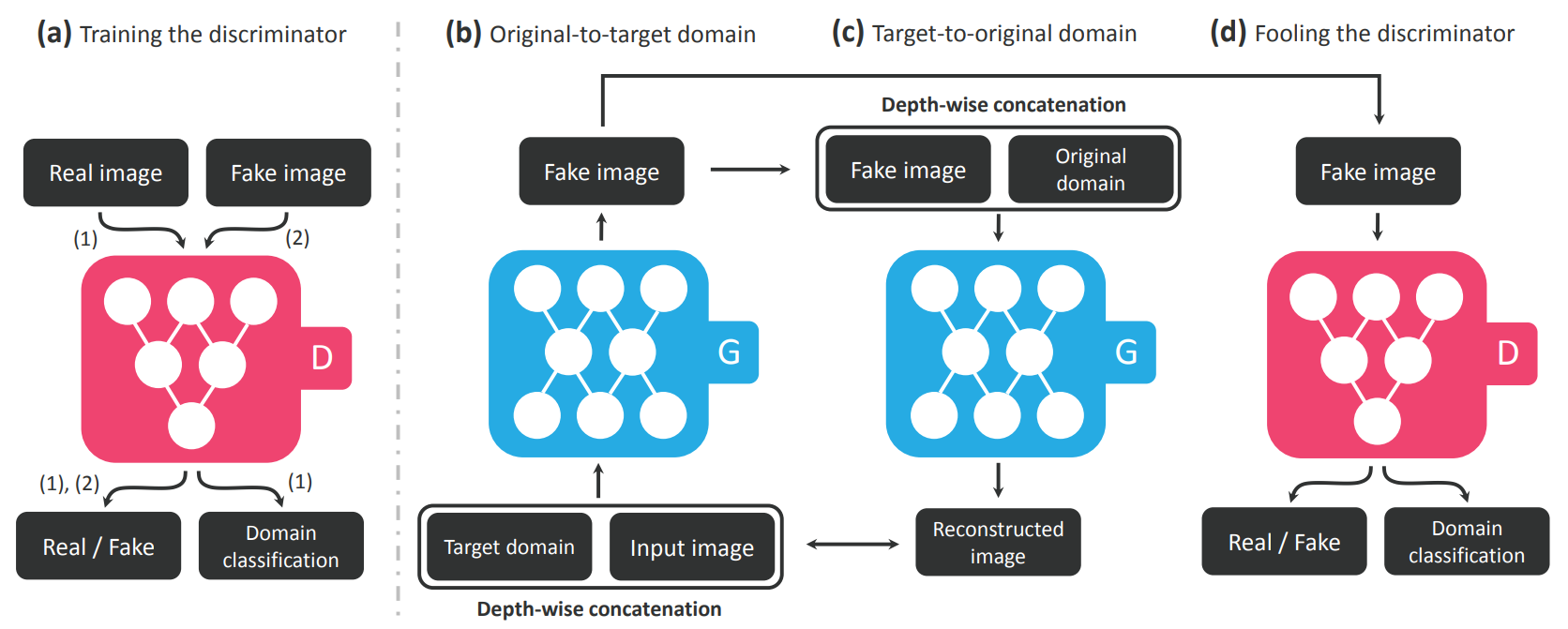
Figure 3. 판별 모델 $D$와 생성 모델 $G$ 두 모듈로 구성된 StarGAN 개요.
(a)는 판별 모델 학습 과정을 보여줍니다. 진짜 이미지던 가짜 이미지던 이미지를 입력받으면 해당 이미지가 진짜인지 가짜인지 판별합니다. 여기까지는 이전의 모델들과 큰 차이가 없지만 StarGAN에서는 domain classification이 추가됩니다. 판별 모델은 입력 받은 이미지가 어떤 도메인을 가지고 있는지 예측하며 이를 domain classification이라 합니다. 실제 데이터셋에는 라벨 값이 함께 있으며 생성 모델이 생성한 이미지에도 어떤 이미지로 변환할지 라벨 값을 넣어 이미지를 변환하기 때문에 진짜 데이터와 가짜 데이터 모두 라벨을 확인할 수 있습니다. 판별 모델을 학습할 때 판별 모델이 예측한 도메인과 실제 도메인 라벨 또는 생성모델이 생성한 이미지의 도메인 라벨과의 차이를 classification loss로 계산해 사용합니다.
(b)는 생성 모델이 이미지를 생성하는 과정입니다. 이미지와 함께 condition으로 목표 도메인(Target domain)에 해당하는 라벨을 입력 값으로 받습니다. 예시로 검은 머리를 가진 젊은 여성의 사진을 나이 든 여성의 사진으로 바꾸고 싶은 경우 사진과 함께 라벨로 [1, 0, 0, 0, 0] (순서대로 검은색 머리, 금색 머리, 갈색 머리, 성별 여/남, 나이 늙음/젊음)을 넣어주면 됩니다. 생성 모델은 이미지를 입력으로 주어진 라벨에 맞는 이미지로 변환한 가짜 이미지를 생성하게 됩니다.
(c)는 CycleGAN에서 소개했던 cycle consistency loss와 같은 의미를 가지고 있습니다. (b)에서 생성한 가짜 이미지에 원본 이미지에 해당 하는 검은 머리, 성별 여, 나이 젊음에 대한 라벨([1, 0, 0, 0, 1])을 주어 원본 이미지와 유사한 Reconstructed 이미지를 만듭니다. Reconstructed 이미지와 원본 이미지 간의 차이를 계산해 Reconstruced Loss로 사용합니다.
(d)는 (b)에서 생성한 가짜 이미지로 판별 모델을 속이는 모습을 표현한 것으로 생성 모델은 판별 모델을 속이기 위한 가짜 이미지를 생성하고 판별 모델은 진짜와 가짜 이미지를 구별하는 adversarial loss를 나타냅니다.
Loss function
StarGAN의 loss는 Adversarial Loss, Domain Classfication Loss, Reconstruction Loss 총 3가지 loss로 구성됩니다.
Adversarial Loss
Adversarial Loss의 수식은 아래와 같습니다.
\[\mathcal{L} _{adv} = \mathbb{E} _x [logD _{src}(x)] + \mathbb{E} _{x, c}[log(1-D _{src}(G(x, c)))]\]$G$는 이미지 $x$와 원하는 도메인인 목표 도메인에 해당하는 라벨 $c$를 입력으로 받아 이미지 $G(x, c)$를 생성하고 $D$는 실제 이미지와 가짜 이미지를 구별하고자 합니다.
StarGAN의 $D$에는 2가지 기능이 있는데 이미지가 실제 데이터셋에서 온 것인지 $G$가 생성한 가짜 이미지에서 온 것인지 구별하는 $D _{src}$와 이미지의 도메인이 진짜인지 가짜인지 구별하는 $D _{cls}$가 있습니다. Adversarial loss에서 $D$는 이미지를 구별하는 것이 목적이기 때문에 $D _{src}$로 표기되어 있습니다.
StarGAN의 학습에서는 학습 프로세스를 안정화하고 더 높은 품질의 이미지를 생성하기 위해 gradient penalty가 있는 Wasserstein GAN을 적용합니다.
GAN에서 KLD와 JSD로 증명을 했었다면 WGAN에서는 EMD(Earth Mover Distance) 또는 Wasserstein distance라 불리는 새로운 방법으로 Generative adversarial loss로 사용하는 것을 제안했습니다. 하지만 Wasserstein distance는 공간이 넓어 탐색하기 힘들며 최소값이 존재한다는 보장도 없었습니다. 이때 Kantorovich-Rubinstein Duality Theorem을 적용해 식을 정리한다면 WGAN 수식이 1-Lipschitz function에 공간에 위치해야 한다는 전제 조건 하에 Adversarial loss로 표현이 가능했습니다.
WGAN은 1-Lipschitz 전제 조건을 만족하기 위해 Weight Clipping을 사용했습니다. Lipschitz는 두 점 사이의 거리를 일정 비 이상으로 증가시키지 않는 함수로 1-Lipschitz는 함수 $f$의 미분계수가 1을 넘어가지 않음을 의미합니다. WGAN은 weight clipping을 사용해 1-Lipchitz를 해결하는데, weight clipping은 가중치 값을 제한함으로써 해결하는 방법입니다. Weight Clipping의 방법으로 기존의 DCGAN과 같은 모델보다 좋은 성능이 나왔으며 CNN, MLP 환경, Batch normalization이 없는 환경에서도 학습이 이루어진 모습을 보여주어 mode collapse 현상 없이 기존의 방법보다 안정적임을 보여주었습니다.
하지만 Weight Clipping은 방법을 소개한 WGAN 논문에서조차 좋지 않은 방법이라 표현하는데, 단순하게 weight를 제한하는 방법일 뿐더러 모델의 성능이 하이퍼 파라미터에 민감하기 때문입니다. 모델의 weight를 $[-c, c]$로 제한한다면 $c$의 값이 하이퍼 파라미터가 됩니다. 이때 $c$의 값이 크면 $[-c, c]$까지 도달하는 시간이 오래 걸려 optimal까지 학습하는 시간이 오래 걸리게 되고 $c$ 값이 작으면 gradient vanishing 문제가 발생하게 됩니다.
이를 해결하기 위해 이후 논문인 WGAN-GP에서는 weight clipping 대신 gradient penalty를 사용합니다. Clipping을 사용하는 대신 gradient norm이 목표 norm 값인 1보다 커지면 모델에 불이익을 주는 방식입니다.
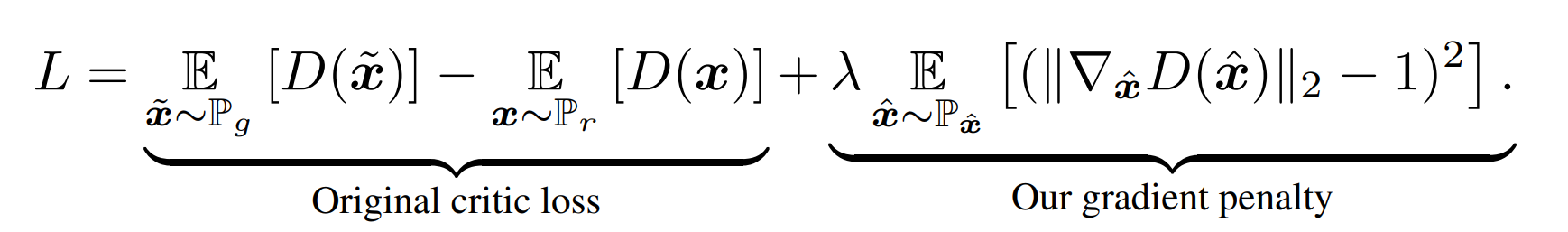
$\hat{x}$는 x와 $\sim{x}$ 사이에서 샘플링된 값으로 실제 데이터와 생성된 가짜 데이터의 모든 점이 될 수 있는 값을 의미합니다. 미분 가능한 함수 $f$에서 어떤 점을 뽑아도 $[\nabla f(\hat{x})] = 1$으로 만들어 1-Lipschitz를 만족하게 만들기 때문에 gradient norm 값이 1과 차이가 난다면 오차를 주도록 차이 값을 제곱해 gradient penalty로 사용합니다.
모델 학습이 사용되는 adversarial loss는 위의 식과 같습니다. 여기서 $\hat{x}$은 실제 이미지와 생성된 이미지 사이의 직선에 따라 균일하게 샘플링되며 모든 실험에서 $\lambda_{gp}=10$을 사용합니다.
참고
- 모끼의 딥러닝 공부 / [논문 읽기] Wasserstein GAN
- 하우론 / [학부생의 딥러닝] GANs WGAN, WGAN-GP : Wassestein GAN(Gradient Penalty)
Domain classification
판별 모델이 이미지를 입력받아 해당 이미지에 대한 도메인이 무엇인지 예측해 라벨을 출력하고 그 라벨과 실제 라벨과의 차이를 Domain classification loss로 사용합니다. Domain classification loss는 2가지로 나뉘는데 $D$에게 실제 데이터를 준 경우와 $G$가 생성한 가짜 데이터를 준 경우로 나눌 수 있습니다.
우선 $D$에게 실제 데이터를 주어 Domain classification loss를 학습할 때 수식은 아래와 같습니다.
\[\mathcal{L}^{\mathcal{r}} _{cls} = \mathbb{E} _{x, c'}[-logD _{cls}(c' | x)]\]수식에서 $c’$는 원본 이미지(실제 데이터 $x$)의 도메인 라벨을 의미하므로 $D _{cls}(c’\mid x)$는 데이터 $x$가 주어졌을 때 $D$가 예측한 $x$의 도메인 라벨을 의미합니다. 위의 $D$를 훈련할 때 위의 목적함수를 최소화함으로써 $D$는 실제 이미지 $x$를 도메인 $c’$로 분류하는 방법을 학습합니다.
다음 수식은 $D$에게 $G$가 생성한 가짜 데이터를 준 경우입니다.
\[\mathcal{L}^{\mathcal{f}}_{cls} = \mathbb{E}_{x, c}[-logD_{cls}(c | G(x, c))]\]생성 모델 $G$는 원본 이미지 $x$와 만들고자 하는 이미지의 목표 도메인 라벨 $c$을 입력으로 받아 가짜 이미지($G(x, c)$)를 생성합니다. 생성된 이미지를 $D$에게 입력으로 주고 $D$는 이 이미지의 라벨이 무엇인지($D _{cls}(c \mid G(x, c))$) 판별합니다. $G$를 훈련할 때 위의 목적함수를 최소화함으로써 $G$는 $D$가 타겟 도메인 라벨인 $c$로 분류할 수 있는 이미지를 생성하는 방법을 학습합니다.
Reconstruction Loss
Adversarial loss와 Classification Loss를 최소화함으로써 $G$는 사실적이고 타겟 도메인 라벨 $c$로 분류되는 이미지를 생성하도록 학습합니다. 그러나 위의 2가지 Loss를 최소화해도 $G$가 입력 이미지의 도메인 관련된 부분들은 변경하도록 이미지를 변환하지만 변환된 이미지가 입력 이미지의 내용을 보존한다고 보장할 수는 없습니다. 이 문제를 완화하기 위해 Cycle Consistency Loss를 생성모델에 적용합니다.
\[\mathcal{L} _{rec} = \mathbb{E} _{x, c, c'}[\| x-G(G(x, c), c') \|_1]\]Cycle Consistency Loss처럼 이미지를 타겟 도메인($c$)에 해당하는 이미지($G(x, c)$)로 변경했다 다시 원본 도메인($c’$)에 해당하는 이미지($G(G(x, c), c’)$)로 변경하는 과정을 거칩니다. 원본 이미지($x$)와 다시 원본 이미지로 재구성된 이미지와의 차이를 L1 norm($ | () |_1 $)으로 계산해 Reconstruction Loss로 사용합니다.
CycleGAN에서는 두 도메인으로 변환하는 생성 모델 2개를 사용했으므로 2개의 모델을 이용해 Cycle Consistency Loss를 계산했지만 StarGAN에서는 하나의 생성모델로 Reconstructed Loss를 계산한다는 차이점이 있습니다.
Full Objective
최종 $G$와 $D$를 최적화하기 위한 목적 함수는 아래와 같습니다.
\[\mathcal{L}_D = - \mathcal{L}_{adv} + \lambda_{cls}\mathcal{L}^{r}_{cls}\] \[\mathcal{L}_G = \mathcal{L}_{adv} + \lambda_{cls}\mathcal{L}^r_{cls} + \lambda_{rec}\mathcal{L}_{rec}\]여기서 $\lambda_{cls}$와 $\lambda_{rec}$은 각 adversarial loss와 비교해 domain clasification loss와 reconstruction loss의 상대적 중요성을 제어하는 하이퍼 파라미터입니다. 모든 실험에서 $\lambda_{cls} = 1$, $\lambda_{rec} = 10$을 사용했다 합니다.
다중 데이터셋 학습
Mask Vector
StarGAN은 다중 데이터셋 학습이 가능한 모델로 다중 데이터셋을 사용할 때는 mask vector를 사용하는데, mask vector는 특정 데이터 셋을 사용하는지 나타내는 역할을 합니다. mask vector로 사용하는 데이터 셋에서 명시적으로 제공되는 라벨에 집중할 수 있도록 하며 $n$차원의 ont-hot 벡터를 사용합니다. $n$은 데이터 셋의 수이고 마스크 벡터는 $m$으로 표현합니다. 논문에서는 CelebA와 RaFD 데이터 셋을 사용하므로 $n = 2$가 됩니다. 만약 모델을 학습할 때 CelebA 데이터 셋을 사용한다면 $m = [1, 0]$이 되고 RaFD 데이터 셋을 사용한다면 $m = [0, 1]$이 됩니다.
전체 학습 과정
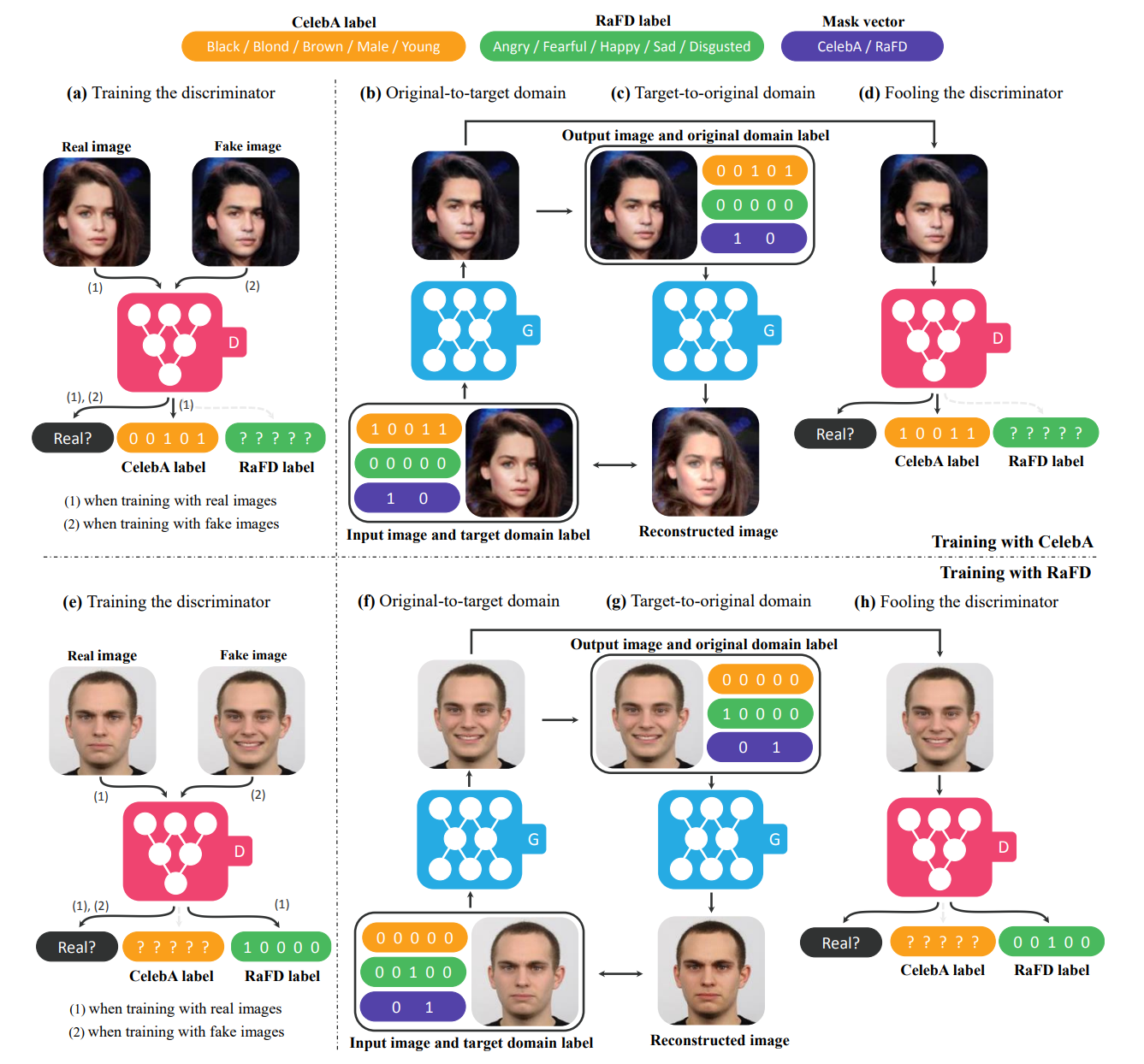
Figure 8. CelebA와 RaFD를 모두 사용한 훈련 시 StarGAN의 개요
Fig8 상단에서 볼 수 있듯이, CelebA의 라벨에는 이진 속성(흑발, 금발, 갈발, 남자, 젊음)이 포함되어 있고, RaFD의 라벨에는 범주형 속성(화남, 두려움, 행복, 슬픔, 혐오)에 대한 정보가 제공됩니다. 마스크 벡터는 2차원 one-hot 벡터로 CelebA 또는 RaFD 라벨이 유효한지 여부를 나타냅니다.
Fig8에서 (a) ~ (d) 는 CelebA를 사용한 훈련 과정, (e) ~ (h) 는 RaFD를 사용한 훈련 과정을 보여줍니다.
(a), (e) 는 판별 모델에 관한 것으로 판별 모델 $D$는 실제 이미지와 가짜 이미지를 구분하고 이미지의 domain을 예측해 domain classification loss를 계산합니다. CelebA 데이터셋을 사용하는 경우 CelebA 라벨의 classification error를 계산해 CelebA 라벨에 대해서만 domain classification loss를 최소화하는 학습을 하고 RaFD 데이터셋을 사용하는 경우에는 RaFD 라벨의 domain classification loss만을 최소화하도록 학습합니다.
(b), (c), (f), (g) 는 생성 모델에 관한 것으로 mask vector(보라색)가 [1, 0]일 때 생성 모델 $G$는 CelebA 라벨(노란색)에 초점을 맞추고 RaFD 라벨(초록색)을 무시하여 image-to-image 변환을 수행하도록 학습하는 것을 보여줍니다. 마스크 벡터가 [0, 1]일 때는 그 반대의 경우로 학습합니다.
(d), (h) 는 adversiral loss에 관한 것으로 $G$는 $D$가 실제 이미지와 가짜 이미지를 구별할 수 없고 목표 도메인에 속하는 것으로 분류할 수 있는 이미지를 생성하려 시도하는 것을 보여줍니다.
다중 데이터셋에서 하나 확인해야 할 것은 데이터셋 간의 크기 차이입니다. StarGAN에서 사용한 CelebA의 장 수는 202,599장이고 RaFD는 4,824장으로 두 데이터셋의 크기 차이가 큽니다. StarGAN에서는 두 데이터셋을 학습하는 epoch 수를 조절했습니다. CelebA에 대해서는 총 20 epoch, RaFD에 대해서는 총 200 epoch을 학습함으로써 데이터셋 간의 크기 차이에 따른 부작용을 줄일 수 있도록 했습니다.
모델
Table4와 Table 5에서 StarGAN의 네트워크 구조를 알 수 있습니다. 표기법은 아래와 같습니다.
- nd : 도메인 수
- nc : 도메인 라벨의 차원
(CelebA와 RaFD 데이터셋을 모두 사용해 학습할 경우 n+2, 그렇지 않으면 nd와 동일) - N : 출력 채널 수
- K : 커널 크기
- S : stride 크기
- P : padding 크기
- IN : Instance Normalization
모델 구조
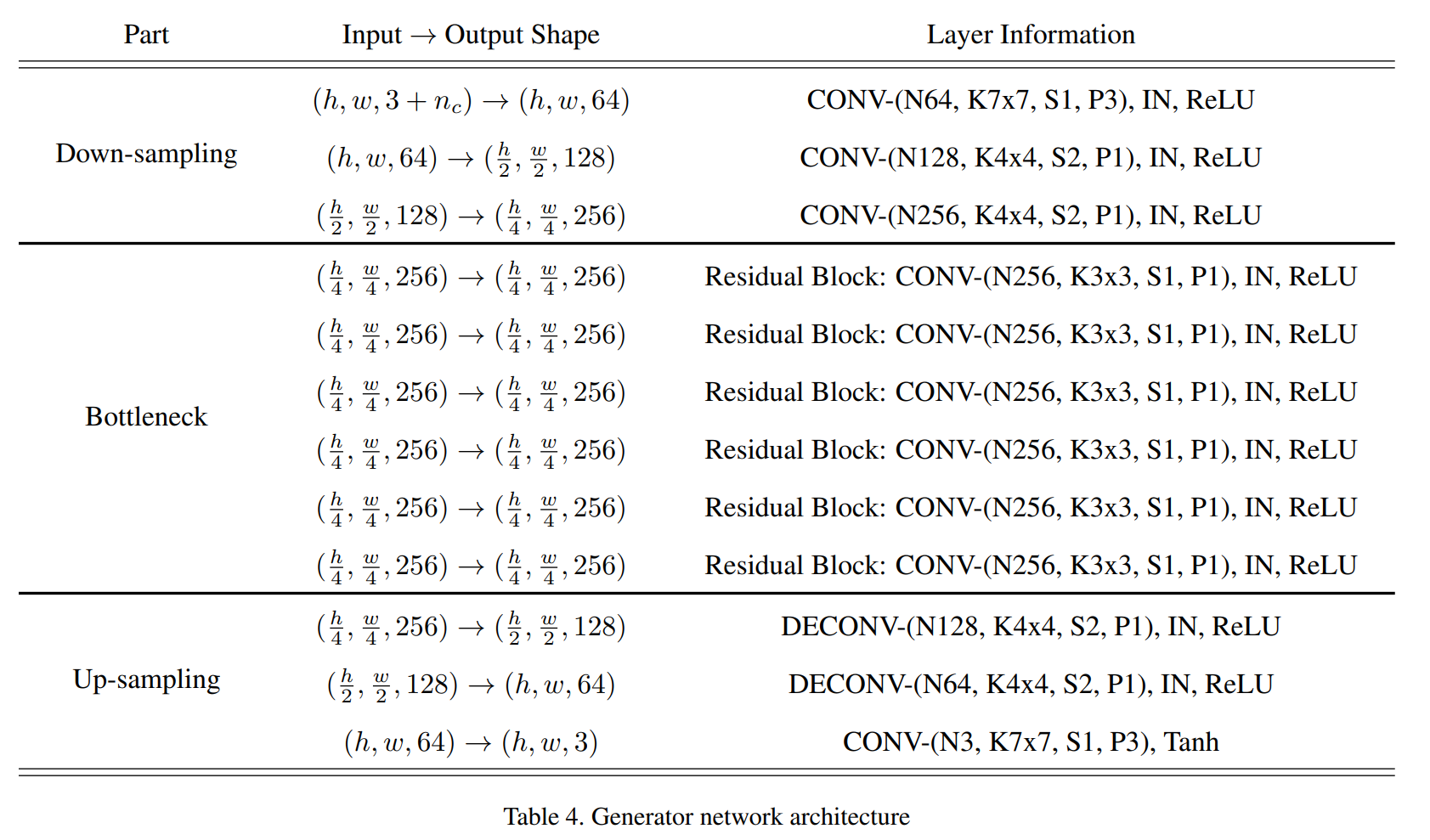
Table 4. 생성 네트워크 구조
CycleGAN 구조를 채택합니다. CycleGAN에서 이미지 크기가 256x256 미만인 경우 6개의 residual block을 사용했었는데 StarGAN도 같은 구조를 사용합니다. 생성 모델의 경우 마지막 출력 레이어를 제외한 모든 레이어에서 instance normalization을 사용합니다.
Table 5. 판별 네트워크 구조
판별 모델 또한 CycleGAN, Pix2Pix에서 사용했던 PatchGAN을 사용합니다. 판별 모델에는 normalization을 사용하지 않으며 Leaky ReLU는 0.01의 negative slope를 사용합니다.
baseline 비교 모델
비교를 위한 baseline 모델로는 두 도메인 간 image-to-image 변환을 수행하는 DIAT과 CycleGAN 그리고 cGAN을 이용해 속성 변환을 수행하는 IcGAN을 baseline 모델로 사용합니다.
결과
단일 데이터셋
데이터 셋 평가에는 Qualative evaluation, Quantitative evaluation 2가지 방식이 사용됩니다. Qualiative evaluation(정성적 평가)로 StarGAN과 baseline 모델들의 결과를 제시하고 Quantitative evaluation(정량적 평가)로는 Pix2Pix와 CycleGAN에서도 등장했던 Amazon Mechanical Turk(AMT)를 사용합니다.
AMT는 설문조사 형식으로 Turker(실험자)는 입력 이미지가 주어지면 느껴지는 이미지의 사실성, 속성 변환 품질, 인물의 기존 정체성 보존을 기준으로 가장 잘 생성된 이미지를 선택합니다. Turker들에게 주어진 이미지 옵션은 4가지로 StarGAN과 basline 모델 3개의 결과 이미지, 총 4개의 이미지를 무작위로 섞은 것입니다.
AMT는 2차례 수행되었으며 한 연구에서는 생성된 이미지에 머리색, 성별, 나이 중 하나의 속성을 변환한 것이였으며 다른 연구에서는 생성된 이미지에 여러 속성의 조합이 포함되어 변환한 것이였습니다. 각 사용자 연구에서 Turker의 수는 단일 및 다중 변환 작업에서 각각 146,100명이였다 합니다.
CelebA
StarGAN은 다중 도메인 변경이 가능한데 DIAT과 CycleGAN은 두 도메인 간의 데이터만 처리할 수 있으니 논문에서는 도메인 페어 별로 모델을 학습해 사용했다 합니다. 예시로 이미지의 머리 색을 갈색에서 검정색으로 바꾸는 작업과 성별을 여성에서 남성으로 바꾸는 작업을 동시에 이미지를 적용하기 위해 갈색 머리 도메인과 검은 색 머리 도메인 간의 변환이 가능한 모델 하나와 여성와 남성 간의 변환이 가능한 모델을 사용하여 머리 색을 변경한 후 성별 속성을 변경합니다.
Qualiative evaluation

Figure 4. CelebA 데이터셋의 얼굴 속성 변환 결과.
Fig.4 는 CelebA의 얼굴 속성 결과를 보여줍니다. 첫 번째 열은 입력 이미지를, 다음 4 열은 단일 속성 변화 결과, 가장 오른쪽 4열은 다중 속성 변환 결과를 보여줍니다. H는 머리 색, G는 성별, A는 나이 변화를 의미합니다.
Cross-domain 모델인 DIAT과 CycleGAN에 비해 결과의 시각적 품질이 더 높은 것을 확인할 수 있었습니다. StarGAN은 overfitting이 발생하기 쉬운 고정된 변환(예. 갈색 머리에서 금색 머리로 변환)을 수행하도록 모델을 학습하지 않고 목표 도메인 라벨에 따라 이미지를 유연하게 변환하도록 학습하기 때문에 regularization 효과를 가지게 됩니다. 이를 통해 StarGAN은 다양한 얼굴 속성 값을 여러 이미지 도메인에 보편적으로 적용할 수 있는 feature를 학습할 수 있습니다.
Quantitative evaluation

Table 1. 단일 속성 변환에서 모델들의 순위를 매기기 위한 AMT 지각 평가. 각 열의 합은 100% 입니다.
Table 1은 단일 속성 변환에 대한 AMT 실험 결과를 보여줍니다. 모든 변환에 대해 StarGAN은 가장 높은 순위를 차지했지만, 성별 변환의 경우 StarGAN 39.1% vs DIAT 31.4%로 득표율 차이가 크게 나지 않는 경우도 있습니다.
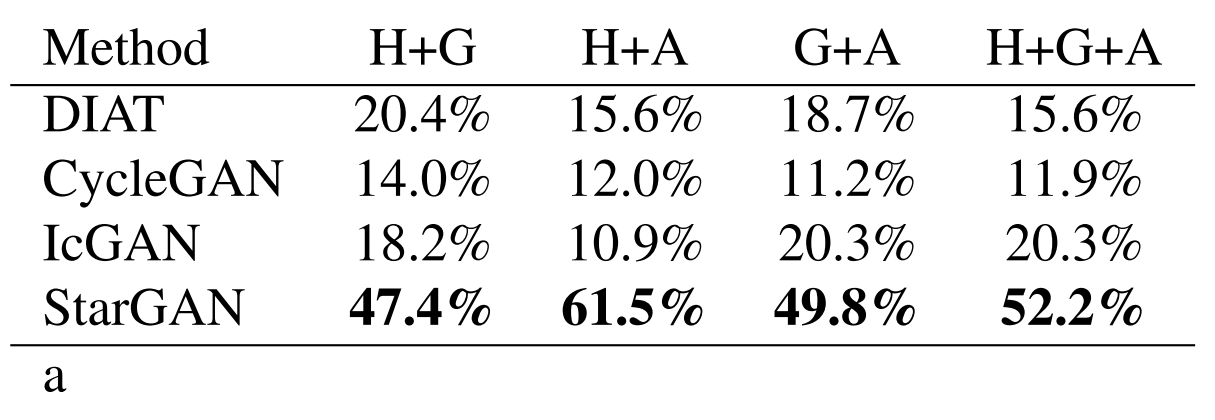
Table 2. 다중 속성 변환에서 모델들의 순위를 매기기 위한 AMT 지각 평가. H: 머리 색, G: 성별, A: 나이
Table 2는 다중 속성 변환 작업에 대한 AMT 결과를 보여줍니다. ‘G+A’와 같이 여러 속성이 변경된 경우 성능 차이가 크게 나타남을 볼 수 있으며 복잡한 다중 속성 변환 작업에서 StarGAN의 장점을 명확하게 보여줍니다.
RaFD
RaFD 데이터셋에서 얼굴 표정을 합성하는 작업을 실험합니다. StarGAN과 baseline 모델들을 비교하기 위해 입력 모데인을 ‘neutral’(중립) 표현으로 고정하고 타겟 도메인은 나머지 7가지 표정 중 하나로 변경합니다.
Qualiative evaluation

Figure 5. RaFD 데이터셋의 얼굴 표정 합성 결과.
Figure 5.에서 볼 수 있듯이 StarGAN은 입력된 개인의 주체성과 얼굴 특징을 적절히 유지하면서 가장 자연스러운 표정을 명확하게 생성합니다. DIAT과 CycleGAN은 대부분 입력된 주체성을 유지하지만, 많은 결과가 흐릿하게 표시되고 입력 이미지에서의 선명도를 유지하지 못합니다. IcGAN은 심지어 남성 이미지를 생성해 이미지의 개인 정체성을 유지하지 못함을 보여줍니다.
논문에서 이미지 품질에서 StarGAN의 우월성은 암시적 데이터 증강 효과에 기인한다고 언급합니다. RaFD 이미지에는 비교적 도메인 당 이미지의 수가 500장 적도록 작아 두 개의 도메인을 학습하는 DIAT 및 CycleGAN은 한 번에 1,000 장의 학습 이미지만 사용할 수 있습니다. StarGAN은 사용 가능한 모든 도메인의 데이터를 활용하므로 8개의 도메인을 사용하는 이번 실험에서는 총 4,000개의 이미지를 사용할 수 있습니다.
Quantitative evaluation
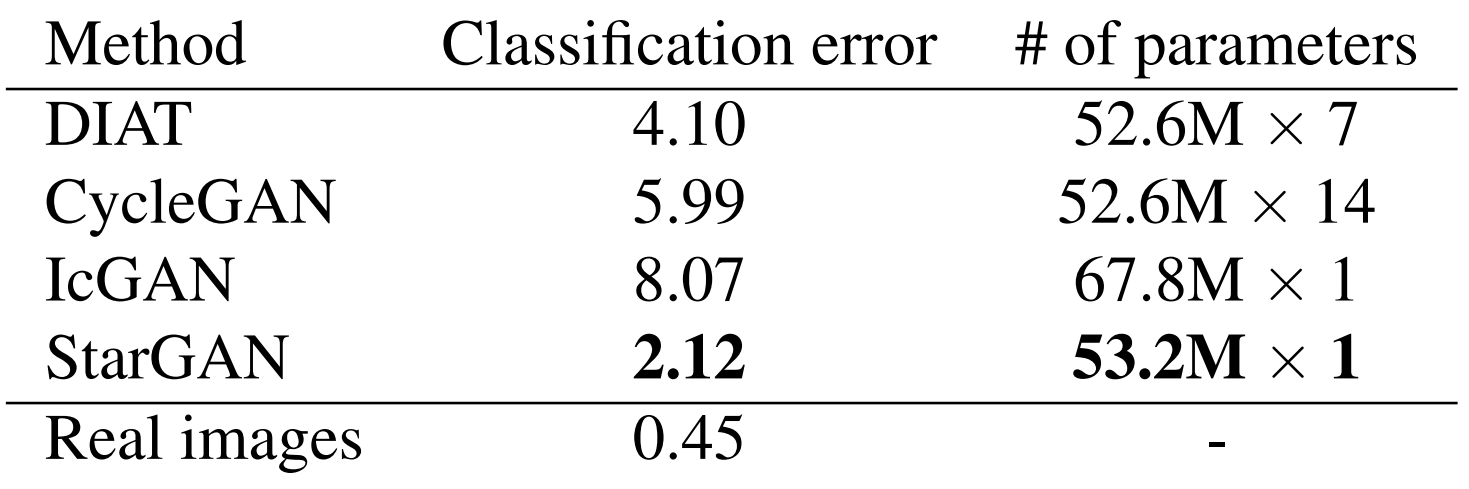
Table 3. RaFD 데이터 셋에서 측정한 분류 오차[%]와 파라미터 수
정량적 평가를 위해 합성된 이미지에서 얼굴 표정의 분류 오차를 계산합니다. ResNet18 구조[5]를 사용해 RaFD 데이터 셋(학습 90%, 테스트 10% 분할)에서 얼굴 표정 분류기를 학습한 결과 99.55%의 거의 완벽에 가까운 정확도를 기록했습니다.
동일한 학습 셋을 사용해 각 이미지 변환 모델을 학습시키고 학습에 사용하지 않았던 테스트 셋에서 이미지 변환을 수행한 후 ResNet18를 이용해 변환된 이미지의 표현을 분류했습니다. Table3에서 볼 수 있듯이 StarGAN은 가장 낮은 분류 오차를 달성했으며 이는 우리 모델이 비교했던 모든 방법 중 가장 사실 적인 얼굴 표정을 생성한다는 것을 나타냅니다.
다중 데이터셋 학습
CelebA와 RaFD 데이터 셋을 모두 학습한 StarGAN 모델을 StarGAN-JNT, RaFD만을 학습한 StarGAN 모델을 StarGAN-SNG로 표기해 마스크 벡터를 이용해 다중 데이터 셋을 학습한 결과를 보여줍니다.
다중 데이터셋 비교

Figure 6.CelebA 데이터셋에서 StarGAN-SNG와 StarGAN-JNT의 얼굴 표정 합성 결과
CelebA의 이미지에 얼굴 표정을 합성에 대한 정성적 비교를 볼 수 있습니다. StarGAN-JNT는 RaFD 데이터셋만 학습하므로 CelebA 이미지를 변환하는 방법을 학습하지 못하며 StarGAN-JNT는 CelebA 데이터 셋을 학습하므로 이미지 변환에 더 나은 결과를 보여줍니다.
마스크 벡터 사용

Figure 7. StarGAN-JNT에 의해서 생성된 이미지로 첫번째 행은 올바른 마스크 벡터를, 두번째 행은 잘못된 마스크 벡터를 적용한 결과를 보여줍니다.
얼굴 표정의 차원을 1로 설정해 ont-hot 벡터 c를 제공했으며 RaFD의 데이터셋을 사용하는 것이므로 적절한 마스크 벡터는 [0, 1]이 됩니다. Fig7은 적절한 마스크 벡터가 주어진 경우와 아닌 경우에 대한 결과를 보여줍니다. 잘못된 마스크 벡터를 사용한 경우, StarGAN-JNT는 얼굴 표정 합성에 실패하고 입력 이미지의 나이를 조작합니다. 이는 모델이 얼굴 표정 라벨을 알 수 없는 것으로 무시하고 얼굴 속성 라벨을 마스크 벡터에 유효한 것으로 취급하기 때문입니다. 얼굴 속성 중 하나가 ‘젊음’이므로 모델은 0 벡터를 입력으로 받을 때 이미지는 젊음에서 늙음으로 변환합니다. 이 동작을 통해 StarGAN이 모든 라벨을 포함한 여러 데이터 셋의 image-to-image 변환에서 마스크 벡터의 의도된 역할을 제대호 학습했음을 확인할 수 있습니다.
StarGAN의 기본적인 모델 구조와 mask vector를 사용한 다중 데이터셋 학습 그리고 그에 따른 결과들까지 논문 리뷰를 해보았습니다.
자세한 모델 구조에 대한 내용은 다음 글이 될 StarGAN(2)-모델 구현에서 알아보아요!
이번 글도 봐주셔서 감사합니다:)