 solee
solee
StarGAN(2) - 논문 구현
StarGAN(1) - 논문 리뷰에 이은 StarGAN 논문 구현 글입니다! StarGAN의 공식 코드는 Github에서 확인하실 수 있습니다.
1. 데이터 셋
논문에서는 The CelebFaces Attributes dataset(CelebA)와 The Radboud Faces Database(RaFD)를 사용해 다중 데이터셋을 사용하는 모델을 구현했습니다. 이 중 RaFD는 대학에서 일하는 연구자임을 연구실 웹페이지 또는 최근 논문들을 이메일을 통해 보여주고 데이터를 얻을 수 있습니다. 저는 소속이 없으니 쿨하게 RaFD 데이터셋 사용을 포기했습니다 ![]()
하지만 다중 데이터셋을 사용한 모델을 만들어본 적이 없어 이번 기회에 다중 데이터셋 모델을 사용해보고 싶었습니다. 그래서 이미지의 양이 상당한 CelebA 데이터 셋을 2개로 나눠 다중 데이터셋처럼 사용하기로 했습니다 ![]()
데이터셋 분리
기존 CelebA 데이터셋에는 총 40개의 속성이 있는데 이 중 몇몇 속성을 선택해 CelebA와 CelebB로 데이터셋을 나누었습니다. CelebA에는 머리 스타일과 관련된 속성들로 Bangs, Black_Hair, Blond_Hair, Brown_Hair, Gray_Hair 5개의 도메인을 선택하고 CelebB에는 얼굴에 추가로 얹을 수 있는 속성, 얼굴의 필수 요소가 아닌 속성들로 Wearing_Earrings, Wearing_Hat, Mustache, Eyeglasses 4개의 도메인을 선택했습니다.
속성 별 데이터 수가 얼마나 되는지 확인하기 위해 우선 데이터를 나눠보기로 했습니다. 기존 데이터셋에서 라벨 속성이 CelebB의 속성이나 CelebA의 속성에 겹치는 것이 있다면 label_celebB와 label_celebA에 모아두고 celebB와 celebA 어디에도 속하지 않는 경우 label_except에 우선 모아두도록 했습니다.
attr = open(path_base + '\\list_attr_celeba.txt', "r")
lines = attr.readlines()
labelname = lines[1].split()
label_celebA = []
label_celebB = []
label_except = []
for line in tqdm(lines[2:]):
unit = line.split()
filename = unit[0]
labels = unit[1:]
indexes = set([i for i in range(40) if labels[i]=='1']) # 현재 이미지 라벨에 해당하는 속성만 모아둠
# celebB 데이터
if len(celebB & indexes) > 0: # celebB와 겹치는 속성이 있는 경우
label_celebB.append(line)
shutil.copyfile(path_dataset + '\\' + filename, path_celebB + '\\' + filename)
# celebA 데이터
elif len(celebA & indexes) > 0: # celebB와는 겹치지 않으나 celebA와 겹치는 속성이 있는 경우
label_celebA.append(line)
shutil.copyfile(path_dataset + '\\' + filename, path_celebA + '\\' + filename)
# except -> 이후 celebA와 celebB 데이터 수에 따라 어디에 넣을지 정해지기 위한 용도
else:
label_except.append(line)
print(len(label_celebA), len(label_celebB), len(label_except))
코드의 마지막 줄인 print() 함수로 CelebA, CelebB, 어디에도 속하지 않는 except의 수를 확인한 결과 각각 96197, 64068, 42334가 출력되었습니다.
StarGAN 논문에서는 CelebA 데이터 수와 RaFD 데이터 수가 크게 차이가 나 각자 데이터 셋을 학습하는 수에 차이를 두었습니다. CelebA는 총 20 epoch, RaFD는 총 200 epoch을 학습했다 되어있습니다. 적절히 비슷한 수로 데이터를 나누면 학습 epoch에 차이를 두지 않아도 된다고 판단했고 except에 해당하는 데이터를 CelebB로 옮긴다면 CelebA와 CelebB의 데이터 수가 비슷하기에 except의 데이터를 아래의 코드로 CelebB에 합쳤습니다.
# except 데이터 celebB로 이동
for line in tqdm(label_except):
unit = line.split()
filename = unit[0]
label_celebB.append(line)
shutil.copyfile(path_dataset + '\\' + filename, path_celebB + '\\' + filename)
print(len(label_celebA), len(label_celebB))
이미지는 shutil.copyfile로 옮겼으니 이미지와 이미지에 해당하는 라벨을 인식할 수 있도록 원본 파일과 같은 형식의 .txt 파일로 라벨 정보를 저장할 수 있도록 아래 코드를 사용했습니다.
def write_label(path_file, label_name, labels):
file = open(path_file, "w")
file.write(str(len(labels)) + '\n')
file.write(' '.join(label_name) + '\n')
for line in labels:
file.write(line)
file.close()
attr_celebA = 'E:\\DATASET\\celeba\\attr_celebA.txt'
attr_celebB = 'E:\\DATASET\\celeba\\attr_celebB.txt'
write_label(attr_celebA, labelname, label_celebA)
write_label(attr_celebB, labelname, label_celebB)
데이터를 CelebA와 CelebB로 분리한 후 속성 별로 속성에 해당하는 이미지와 해당하지 않는 이미지의 수를 확인해보았습니다.
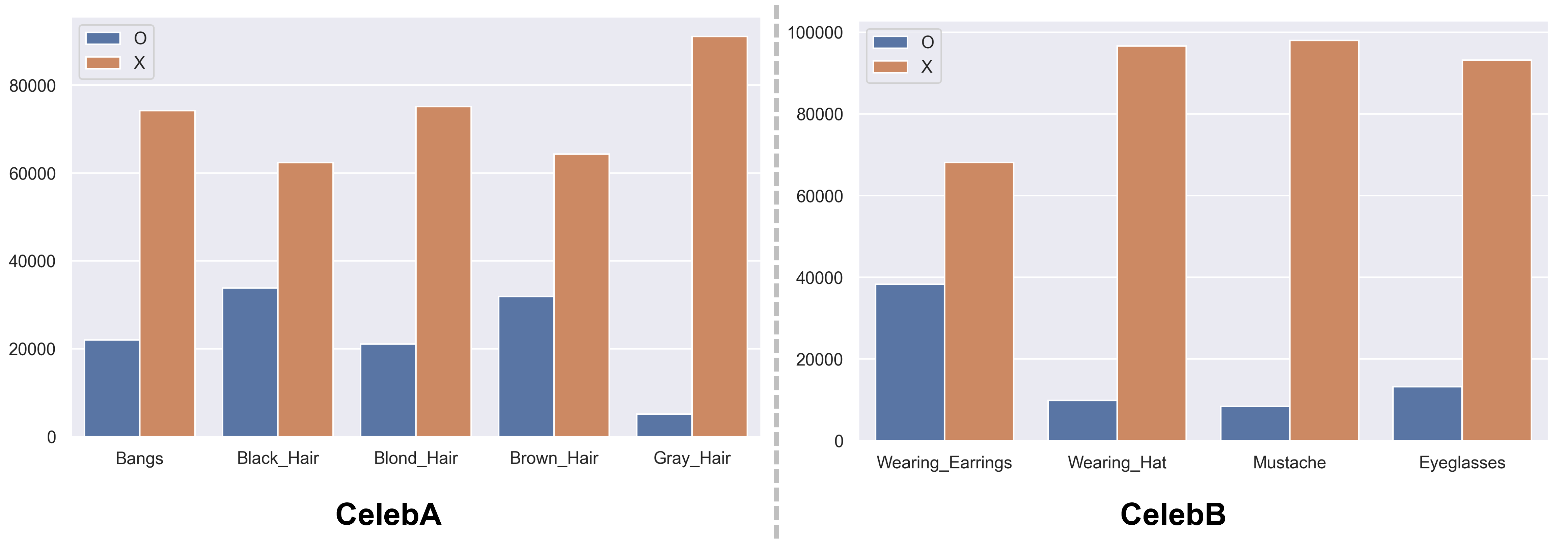
약 10000 장 이상씩 속성에 해당하는 데이터들이 있으나 Gray_Hair는 데이터의 수가 적네요… 모델이 데이터의 수가 적어도 잘 수행할 수 있는지 확인해 볼 수 있을 것 같습니다.
데이터셋 처리
기존 데이터셋을 원하는 속성을 선택해 CelebA와 CelebB로 나누었으니 이미지와 라벨을 데이터로 사용할 수 있도록 Dataset과 DataLoader를 만들어 봅시다!
CelebA와 CelebB 모두 기존 데이터셋과 같은 형식의 데이터셋이니 같은 방법으로 처리할 수 있도록 Class Celeb Dataset을 만들었습니다. attr_label 함수를 통해 라벨 값이 있는 txt 파일을 읽은 뒤 한 줄씩 라벨 인식을 진행합니다.
위에서 선택했던 도메인 라벨 위치에 해당하는 idx 값을 읽어 해당 값이 1인 경우 목표 도메인 속성에 해당하는 이미지이니 True로, 값이 0인 경우는 False로 라벨 값을 작성합니다. 나중에 dataloader의 호출로 getitem 함수로 이미지와 라벨을 출력할 때는 FloatTensor로 라벨 값을 변경하기 때문에 True, False가 아닌 1.0, 0.0의 값으로 출력됩니다.
class Celeb(Dataset):
def __init__(self, path, name, target, transform = None):
self.path_dataset = path + '\\' + name # 이미지 폴더 위치
self.path_attr = path + '\\attr_' + name + '.txt' # 라벨 텍스트 위치
self.target = target
self.transform = transform
self.images = []
self.labels = []
self.label_name = []
self.target_idx = []
self.attr_label()
def attr_label(self):
lines = [line.rstrip() for line in open(self.path_attr, 'r')] # 라벨 값을 전부 읽는다
self.label_name = lines[1].split()
self.target_idx = [self.label_name.index(item) for item in self.target]
for line in lines[2:]:
unit = line.split()
self.images.append(unit[0])
self.labels.append([unit[1:][idx] == '1' for idx in self.target_idx]) # 목표 라벨의 해당하는 값을 True, 그 외는 False으로 기록
def __getitem__(self, idx):
image = Image.open(self.path_dataset + '\\' + self.images[idx])
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, torch.FloatTensor(label)
def __len__(self):
return len(self.labels)
Dataset을 만들었으니 데이터에 적용할 transform과 데이터를 불러올 Dataloader를 만들어야 합니다.
StarGAN에서는 178x218 크기의 원본이미지를 178x178 크기로 crop한 후 128x128 크기로 이미지를 resize하며, $p=0.5$로 Horizontal Flip을 수행합니다. transforms를 이용해 같은 작업을 수행하도록 작성했습니다.
Celeb Dataset에 데이터셋의 위치 값과 원하는 목표 도메인, transform까지 인자로 넣어 CelebA와 CelebB 데이터셋에 대한 객체를 만들어 준 후 DataLoader에 batchsize(16), shuffle, droplast와 함께 인자로 넣어 dataloader를 만들었습니다.
transform = transforms.Compose([
transforms.CenterCrop((178, 178)),
transforms.Resize((128, 128)),
transforms.RandomHorizontalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
targetA = ['Bangs', 'Black_Hair', 'Blond_Hair', 'Brown_Hair', 'Gray_Hair']
targetB = ['Wearing_Earrings', 'Wearing_Hat', 'Mustache', 'Eyeglasses']
datasetA = Celeb('E:\DATASET\celeba', 'celebA', targetA, transform=transform)
datasetB = Celeb('E:\DATASET\celeba', 'celebB', targetB, transform=transform)
dataloaderA = DataLoader(dataset=datasetA, batch_size=batch_size, shuffle=True, drop_last=True)
dataloaderB = DataLoader(dataset=datasetB, batch_size=batch_size, shuffle=True, drop_last=True)
마지막으로 데이터 이미지와 라벨이 잘 들어갔는지 확인하기 위해 아래의 코드로 dataloader의 출력 값을 확인해봤습니다. CelebA와 CelebB 모두 9장씩 총 18장의 이미지와 라벨 값을 출력해보겠습니다.
imageA, labelA = next(iter(dataloaderA))
imageB, labelB = next(iter(dataloaderB))
def show_data(image, label, label_name):
plt.figure(figsize=(8,8))
plt.suptitle(label_name)
for i in range(1, 10):
plt.subplot(3, 3, i)
plt.imshow(transforms.functional.to_pil_image(0.5 * image[i] + 0.5))
plt.title(re.sub(r'[^\d]', '', str(label[i])))
plt.axis('off')
plt.tight_layout()
plt.savefig('./history/data.png', dpi=300)
plt.show()
show_data(imageA, labelA, targetA)
show_data(imageB, labelB, targetB)

CelebA의 (2, 2)에는 머리 상단 부분을 억지로 늘린 이미지, CelebB의 (2, 3)에는 워터마크가 포함된 이미지가 보이네요. 이미지의 퀄리티가 다 좋은 것만은 아닌 것 같습니다. CelebB의 (3, 2)에는 물안경을 쓴 남자 이미지가 있는데 Eyeglasses의 라벨 값으로는 0이 들어가 있는 걸보니 물안경은 안경에 포함되지 않는 것 같습니다 ![]()
2. 모델
StarGAN의 생성 모델은 CycleGAN의 구조를, 판별 모델은 PatchGANs의 구조를 사용합니다. 두 모델의 구조는 Table 4와 Table 5를 통해 확인할 수 있습니다.
Table에서 사용하는 표기에서 $nd$는 도메인의 수, $nc$는 도메인 라벨의 차원을 의미합니다. 제 경우 CelebA의 도메인 수는 5개이고 CelebB의 도메인 수는 4개이므로 $nd = 9$가 됩니다. $nc$는 사용하는 데이터 셋의 수에 따라 달라지는데 저는 2개의 데이터 셋을 사용하므로 $nd$ 값에 2를 더해 $nc = 11$가 됩니다.
- nd : 도메인 수
- nc : 도메인 라벨의 차원 (CelebA와 RaFD 데이터셋을 모두 사용해 학습할 경우 n+2, 그렇지 않으면 nd와 동일)
Generator
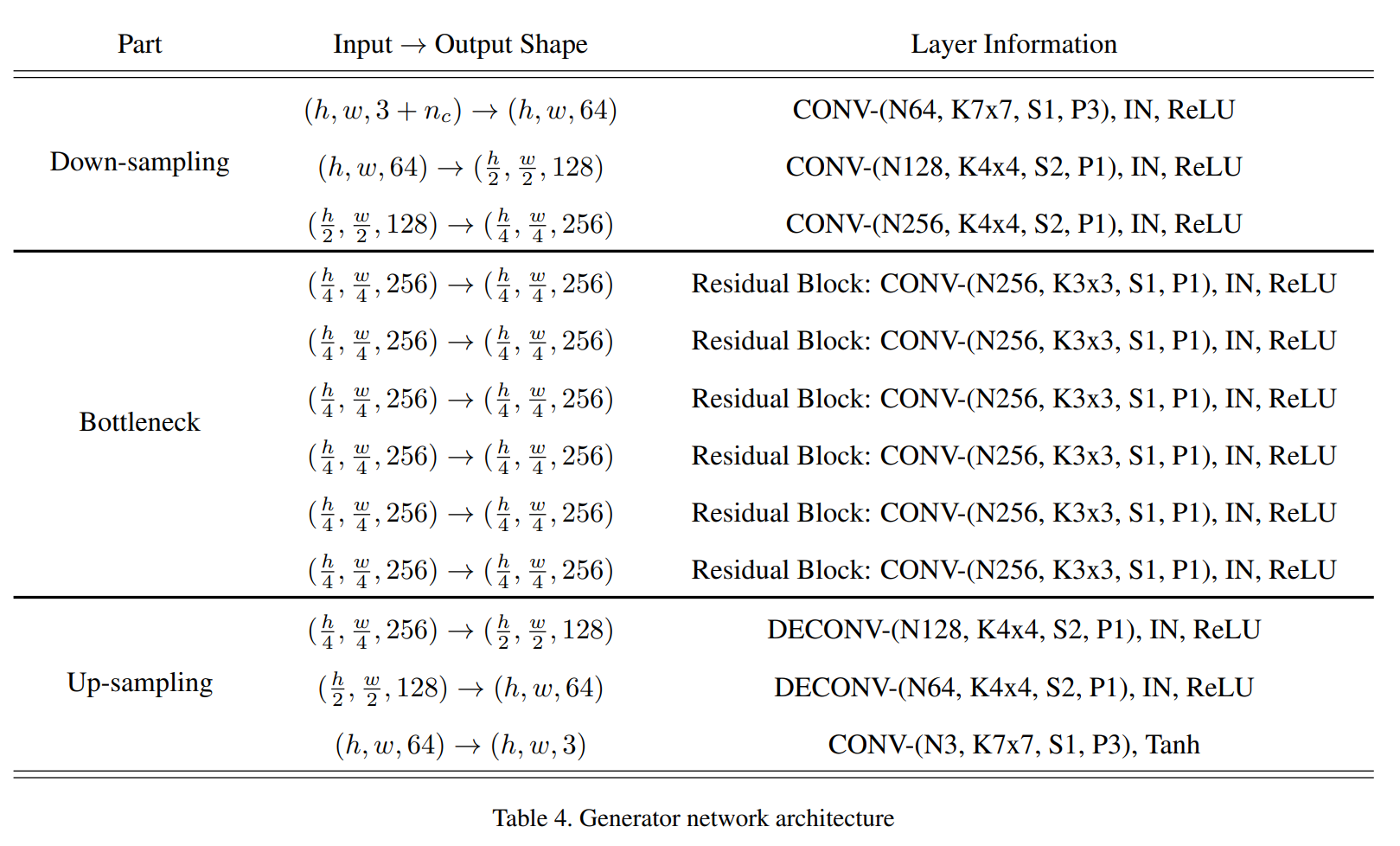
Bottleneck 부분의 Residual Block은 CycleGAN(2) - 논문구현에서 사용했던 Residual Block 코드를 사용했습니다. 변경된 점은 padding으로 CycleGAN에서는 Reflection padding을 사용했었습니다. 하지만 StarGAN에서는 라벨이 이미지와 concat되어 주어지므로 Reflection Padding을 사용하게 된다면 모델의 라벨 인식에 영향을 주어 라벨이 제대로 동작을 하지 않을 수 있습니다. 따라서 padding을 주되 CycleGAN처럼 Reflection padding을 사용하지는 않습니다.
class Residual(nn.Module):
def __init__(self, in_feature, out_feature):
super(Residual, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_feature, out_feature, kernel_size=3, padding=1),
nn.InstanceNorm2d(out_feature),
nn.ReLU(),
nn.Conv2d(in_feature, out_feature, kernel_size=3, padding=1),
nn.InstanceNorm2d(out_feature),
nn.ReLU()
)
def forward(self, x):
return x + self.model(x)
그 외의 Down-sampling과 Up-sampling 부분에 해당하는 Convolution과 DeConvolution(Transposed Convolution)은 각각 클래스로 만들어 ‘Convolution - InstanceNorm - ReLU’ 순으로 적용할 수 있도록 구현했습니다.
class Conv(nn.Module):
def __init__(self, in_feature, out_feature, k, s, p):
super(Conv, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_feature, out_feature, kernel_size=k, stride=s, padding=p),
nn.InstanceNorm2d(out_feature),
nn.ReLU()
)
def forward(self, x):
return self.model(x)
class Deconv(nn.Module):
def __init__(self, in_feature, out_feature, k, s, p):
super(Deconv, self).__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(in_feature, out_feature, k, s, p),
nn.InstanceNorm2d(out_feature),
nn.ReLU()
)
def forward(self, x):
return self.model(x)
위의 클래스들을 가져와 Table 4와 같은 구조로 구현한 Generator입니다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
# down-sampling
Conv(14, 64, 7, 1, 3),
Conv(64, 128, 4, 2, 1),
Conv(128, 256, 4, 2, 1),
# 6 residual block(bottleneck)
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
# up-sampling
Deconv(256, 128, 4, 2, 1),
Deconv(128, 64, 4, 2, 1),
nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=3),
nn.Tanh()
)
def forward(self, x, c):
c = c.view(*c.size(), 1, 1) # [16, 11, 1, 1]
c = c.repeat(1, 1, 128, 128) # [16, 11, 128, 128]
x = torch.cat((x, c), 1) # [16, 14(3+11), 128, 128]
return self.model(x)
생성 모델 $G$의 입력으로 들어오는 것은 원본 이미지인 $x$와 목표 라벨인 $c$입니다. $x$와 $c$의 채널을 합치기 위해서 라벨 $c$의 모양을 [batchsize, nc]에서 [batchsize, nc, h, w]로 변형해 줍니다. 이후 $x$와 $c$를 concat해 모델의 최종 입력의 모양은 [batchsize, nc+3, h, w]가 됩니다. 제 경우 $nc = 11$이고 $h, w = 128$이므로 최종 입력 값의 형태는 [16, 14, 128, 128]이 됩니다.
Discriminator

판별 모델 또한 CycleGAN에서 사용했던 PatchGAN이지만 CycleGAN에서는 256x256 크기 이미지 기준 70x70 Patch을 사용하고 StarGAN에서는 128x128 크기 이미지 기준으로 2x2 Patch를 사용해 최종 형태가 다르다보니 CycleGAN에서 사용했던 코드를 그대로 사용하지는 못했지만 Table 5에 구조가 잘 나와있어 그대로 따라 구현해 보았습니다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.hidden = nn.Sequential(
# input layer
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01),
# hidden layer
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01),
nn.Conv2d(512, 1024, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01),
nn.Conv2d(1024, 2048, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.01)
)
# output layer
self.src = nn.Conv2d(2048, 1, kernel_size=3, stride=1, padding=1)
self.cls = nn.Conv2d(2048, 9, kernel_size=2, stride=1, padding=0) # 5 : CelebA / 4 : CelebB
def forward(self, x):
hidden = self.hidden(x)
x_src = self.src(hidden)
x_cls = self.cls(hidden)
return x_src, x_cls
이미지가 진짜인지 가짜인지 판별하는 PatchGAN 역할은 x_src로 출력하고 이미지의 도메인이 무엇인지 예측하는 부분은 x_cls로 출력합니다. 도메인을 예측하는 cls는 각자 선택한 도메인의 수에 따라 달라지는데 저는 celebA의 도메인 수는 5 개이고 CelebB의 도메인 수는 4 개이므로 9(5+4)가 self.cls의 out_feature가 됩니다.
3. 학습
Adversarial Loss
이전 글인 StarGAN(1) - 논문 리뷰에서 나왔던 것처럼 StarGAN은 Adversarial loss로 WGAN의 Wasserstein Distance(Earth Mover Distance)와 WGAN-GP의 Gradient Penalty를 사용합니다.
\[\mathcal{L} _{adv} = \mathbb{E} _x[D _{src}(x)] - \mathbb{E} _{x, c}[D _{src}(G(x, c))] - \lambda _{gp}\mathbb{E} _{\hat{x}}[(\| \nabla _{\hat{x}}D _{src}(\hat{x}) \|_2 - 1)^2]\]지금까지 계속 사용하던 adversarial loss가 Wasserstein Distance로 변경되면서 $\mathbb{E} _x[log D(x)]$에서 $\mathbb{E} _x[D(x)]$로, $\mathbb{E} _{x, c}[log(1-D(G(x, c)))]$는 $\mathbb{E} _{x, c}[D(G(x, c))]$로 변경되어 log loss를 사용하지 않는 것을 확인할 수 있습니다.
$\mathbb{E} _x[D(x)]$와 $\mathbb{E} _{x, c}[D(G(x, c))]$는 mean 값을 사용해 loss를 계산할 수 있습니다. 이때 판별 모델을 학습할 때에는 gradient_penalty를 적용해야 하며 gradient penalty에 해당하는 수식인 $\mathbb{E} _{\hat{x}}[(\parallel \nabla _{\hat{x}}D _{src}(\hat{x}) \parallel _2 - 1)^2]$를 계산하기 위한 gradient_penalty 함수를 만들었습니다. gradient_penalty 함수의 입력 값은 2개로 generator가 생성한 가짜 이미지와 진짜 이미지 사이의 $\hat{x}$ 그리고 $\hat{x}$을 입력으로 받은 discriminator의 판별 결과입니다.
# 판별 모델 학습시 사용하는 코드입니다.
# 전체 코드는 글 아래의 Github 코드에서 확인하실 수 있습니다.
def gradient_penalty(x, y):
gradients, *_ = torch.autograd.grad(outputs=y,
inputs=x,
grad_outputs=y.new_ones(y.shape),
create_graph=True)
gradients = gradients.view(gradients.size(0), -1) # norm 계산을 위한 reshape
norm = gradients.norm(2, dim=-1) # L2 norm
return torch.mean((norm -1) ** 2) # mse (norm - 1)
# classify real
real_crs, real_cls = discriminator(images)
real_cls = real_cls[:, :len_targetA] if i%2 ==0 else real_cls[:, len_targetA:]
# classify fake
fake_images = generator(images, fake_condition)
fake_crs, _ = discriminator(fake_images)
# gradient penalty
eps = torch.rand(1).cuda()
x_hat = (eps * images + (1 - eps) * fake_images)
crs_hat, _ = discriminator(x_hat)
loss_gp = gradient_penalty(x_hat, crs_hat)
# adv loss
loss_adv = torch.mean(real_crs) - torch.mean(fake_crs) - lambda_gp * loss_gp
$\hat{x}$은 진짜 이미지와 가짜 이미지 사이 어떤 값이든 될 수 있습니다. 따라서 random 값으로 두 이미지 사이의 비율을 의미하는 eps를 만들어 두 이미지 사이의 이미지 값인 x_hat($\hat{x}$)을 만들어줍니다. 그리고 x_hat을 discriminator의 입력으로 넣어 이 이미지에 대한 진짜, 가짜 이미지 판별 결과인 crs_hat이 $D _{src}(\hat{x})$를 나타내며 x_hat과 함께 gradient_penalty 함수의 입력 값이 됩니다.
gradient_penalty 함수는 입력 x가 출력 y가 될 때까지 연산들에 대한 gradient 값을 gradients 변수에 저장합니다. gradients 변수의 크기는 grad_outputs에 입력한 변수와 같은 크기로 변수에 곱해져서 나오게 되니 입력값으로 곱셈에 대한 항등원인 1로 채워진 원하는 크기를 가진 값을 넣어줘야 합니다. $y$에 해당하는 $D _{src}(\hat{x})$, 즉 crs_hat과 같은 크기의 1로 채워진 행렬을 grad_outputs에 넣어주었습니다.
계산된 gradients는 $\parallel \nabla _{\hat{x}}D _{src}(\hat{x}) \parallel _2$를 위해 reshape 한 후 L2 norm인 torch.norm(p=2)을 적용했습니다. 마지막으로 계산한 L2 norm에 -1한 값에 제곱한 값을 mean 함수에 적용한 후 return해 $\mathbb{E} _{\hat{x}}[(\parallel \nabla _{\hat{x}}D _{src}(\hat{x}) \parallel _2 - 1)^2]$ 수식에 대한 계산을 완료했습니다! loss에 적용할 때는 $\lambda _{gp}$를 의미하는 lambda_gp 값을 곱해 adversarial loss에 사용합니다.
Classification Loss
Classification Loss는 Discriminator가 이미지의 도메인을 예측하고 라벨과의 차이를 계산합니다. 판별 모델은 주어진 이미지가 어떤 도메인에 속해있는지 잘 맞출 수 있게 되고 생성 모델은 주어진 가짜 도메인에 해당하는 이미지를 만들 수 있게 됩니다. 라벨은 one-hot 또는 binary 벡터 형식이 가능하며 저는 one-hot 벡터를 사용했습니다. one-hot 벡터 2개(정답 라벨, 예측 라벨) 간의 차이를 계산하기 위해 nn.BCEWithLogitsLoss()를 사용했습니다.
첫번째 수식은 Discriminator 학습 시 사용하며 Classification Loss를 계산하기 위해 실제 라벨과 $D$가 예측한 도메인 라벨과의 차이를 계산합니다. 반대로 Generator 학습 시에는 두번째 수식을 사용하고 Classification Loss를 계산할 때 $G$에게 가짜 이미지를 만들 때 넣어주는 가짜 라벨과 그 가짜 라벨과 원본 이미지를 이용해 $G$가 만든 가짜 이미지를 $D$에게 입력으로 주어 $D$가 예측한 도메인 라벨과의 차이를 계산합니다.
$G$에게 가짜 이미지를 만들 때 넣어주는 가짜 라벨은 generate_label() 함수를 이용해 만듭니다. 입력으로 들어오는 라벨과 같은 크기의 행렬을 만들고 rand 함수를 이용해 $[0, 1)$에 해당하는 값을 부여합니다. 이 중 0.5 초과인 것만 1이 되도록 해 0과 1의 값들이 랜덤하게 행렬에 들어가 있도록 만들었습니다.
def generate_label(label):
fake_label = torch.rand(label.size())
fake_label = ((0.5 > fake_label).float() * 1).cuda()
return fake_label
loss_bce = nn.BCEWithLogitsLoss()
'''
Discriminator 학습 시
'''
# classify real
real_crs, real_cls = discriminator(images)
real_cls = real_cls[:, :len_targetA] if i%2 ==0 else real_cls[:, len_targetA:]
# cls loss
loss_cls = loss_bce(real_cls.squeeze(), labels)
'''
Generator 학습 시
'''
fake_labels = generate_label(labels)
fake_condition = torch.cat([fake_labels, label_ignore, mask], dim=1)
# generate fake
fake_images = generator(images, fake_condition)
fake_crs, fake_cls = discriminator(fake_images)
fake_cls = fake_cls[:, :len_targetA] if i % 2 == 0 else fake_cls[:, len_targetA:]
# cls loss
loss_cls = loss_bce(fake_cls.squeeze(), fake_labels)
Reconstruction Loss
\[\mathcal{L} _{rec} = \mathbb{E} _{x, c, c'}[\| x-G(G(x, c), c') \|_1]\]Reconstruction Loss는 generator가 만든 가짜 이미지($G(x, c)$)를 다시 원본 이미지의 라벨($c’$)을 이용해 $G$가 원본 이미지와 비슷한 가짜 이미지($G(G(x, c), c’)$)를 만들고 이를 원본 이미지($x$과 비교하는 과정을 거칩니다. 비교 후 두 이미지 간의 차이는 L1 norm으로 계산하기 때문에 nn.L1Loss를 사용해 계산했습니다.
loss_l1 = nn.L1Loss().cuda()
# generate fake
fake_images = generator(images, fake_condition)
# rec loss
recon_images = generator(fake_images, condition)
loss_rec = loss_l1(recon_images, images)
Mask Vector
CelebA와 CelebB, 다중 데이터셋을 학습하기 때문에 Mask Vector를 사용했습니다. Mask 벡터는 현재 어떤 데이터셋을 사용 중인지 알려주는 역할을 합니다. CelebA를 사용한다면 [1, 0], CelebB를 사용한다면 [0, 1]을 mask 벡터로 사용합니다.
생성 모델에 라벨을 줄때에는 사용하는 데이터셋에 따라 라벨의 모양이 달라집니다. 예시로 CelebA 데이터셋을 사용 중이라면 입력으로 받은 라벨 ([batch_size, 5]), 사용하지 않는 CelebB의 크기로 만들어졌으며 라벨 정보를 무시하기 위해 0으로 채워진 라벨([batch_size, 4]), 마스크 벡터([batch_size, 2])을 합치게 됩니다.
만약 batch_size가 1일 때 입력받은 CelebA의 라벨이 [[1, 0, 1, 0, 0]]이라면 0으로 채워진 CelebB의 라벨 [[0, 0, 0, 0]]과 마스크 벡터 [[1, 0]]이 합쳐져 최종 라벨은 [[1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0]]이 됩니다.
반대로 CelebB 데이터셋을 사용 중이여서 입력받은 라벨이 [[0, 0, 1, 0]]이라면 0으로 채워진 CelebA의 라벨 [[0, 0, 0, 0, 0]]과 마스크 벡터 [[0, 1]]이 합쳐져 [[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1]]이 됩니다.
fake_labels = generate_label(labels)
if i == 0: # CelebA
mask = torch.cat([ones, zeros], dim=1)
label_ignore = torch.zeros(batch_size, 4).cuda()
condition = torch.cat([labels, label_ignore, mask], dim=1)
fake_condition = torch.cat([fake_labels, label_ignore, mask], dim=1)
else: # CelebB
mask = torch.cat([zeros, ones], dim=1)
label_ignore = torch.zeros(batch_size, 5).cuda()
condition = torch.cat([label_ignore, labels, mask], dim=1)
fake_condition = torch.cat([label_ignore, fake_labels, mask], dim=1)
Scheduler
Scheduler는 CycleGAN 때와 같습니다! StarGAN 논문에서 CelebA와 RaFD 데이터를 학습할 때 CelebA는 전체 20 epoch을 학습시키고 10 epoch 부터 learning rate를 linear하게 줄였고 RaFD는 전체 200 epoch을 학습시키고 중간인 100 epoch 부터 learning rate를 linear하게 줄였다고 합니다.
scheduler_lambda = lambda epoch: 1.0 - max(0, epoch - n_epoch//2 - 1) / float(n_epoch)
scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=scheduler_lambda)
scheduler_D = torch.optim.lr_scheduler.LambdaLR(optimizer_D, lr_lambda=scheduler_lambda)
저는 CelebA 데이터를 제 임의로 비슷한 양으로 나눈 CelebA와 CelebB 데이터를 사용했고 논문의 CelebA 데이터 같이 전체 20 epoch을 학습시키되 10 epoch 부터 learning rate를 줄이도록 설정했습니다. 아래의 그림을 통해 epoch에 따라 줄어드는 learning rate를 확인할 수 있습니다.

학습 코드
학습 부분에 대한 코드입니다. 이때 $G$와 $D$의 학습 비율에 차이를 두어야 합니다. 학습 비율 차이 또한 WGAN에서 가져온 것으로 WGAN의 경우 $D : G = 5 : 1$ 로 $D$를 5번 학습할 때 $G$는 1번 학습하는 방법을 사용했습니다. datalodaer가 데이터를 가져올 때 enumerate로 idx를 부여해 idx가 5의 배수인 경우 (idx % 5 == 0) $G$를 학습하게 해 $D : G = 5 : 1$을 유사하게 맞출 수 있도록 했습니다.
def generate_label(label):
fake_label = torch.rand(label.size())
fake_label = ((0.5 > fake_label).float() * 1).cuda()
return fake_label
for epoch in range(n_epoch):
time_start = datetime.now()
for i in range(2):
if i == 0:
dataloader = dataloaderA
else:
dataloader = dataloaderB
for idx, (images, labels) in enumerate(dataloader):
images = images.cuda()
labels = labels.cuda()
'''
label
'''
fake_labels = generate_label(labels)
if i == 0:
mask = torch.cat([ones, zeros], dim=1)
label_ignore = torch.zeros(batch_size, 4).cuda()
condition = torch.cat([labels, label_ignore, mask], dim=1)
fake_condition = torch.cat([fake_labels, label_ignore, mask], dim=1)
else:
mask = torch.cat([zeros, ones], dim=1)
label_ignore = torch.zeros(batch_size, 5).cuda()
condition = torch.cat([label_ignore, labels, mask], dim=1)
fake_condition = torch.cat([label_ignore, fake_labels, mask], dim=1)
'''
Discriminator
'''
optimizer_D.zero_grad()
# classify real
real_crs, real_cls = discriminator(images)
real_cls = real_cls[:, :len_targetA] if i%2 ==0 else real_cls[:, len_targetA:]
# classify fake
fake_images = generator(images, fake_condition)
fake_crs, _ = discriminator(fake_images)
# gradient penalty
eps = torch.rand(1).cuda()
x_hat = (eps * images + (1 - eps) * fake_images)
crs_hat, _ = discriminator(x_hat)
loss_gp = gradient_penalty(x_hat, crs_hat)
# adv loss
loss_adv = torch.mean(real_crs) - torch.mean(fake_crs) - lambda_gp * loss_gp
# cls loss
loss_cls = loss_bce(real_cls.squeeze(), labels)
# total
loss_D = -loss_adv + lambda_cls * loss_cls
history['D'].append(loss_D.item())
# update
loss_D.backward()
optimizer_D.step()
'''
Generator
'''
if idx % 5 == 0:
optimizer_G.zero_grad()
# generate fake
fake_images = generator(images, fake_condition)
fake_crs, fake_cls = discriminator(fake_images)
fake_cls = fake_cls[:, :len_targetA] if i % 2 == 0 else fake_cls[:, len_targetA:]
# adv loss
loss_adv = -torch.mean(fake_crs)
# cls loss
loss_cls = loss_bce(fake_cls.squeeze(), fake_labels)
# rec loss
recon_images = generator(fake_images, condition)
loss_rec = loss_l1(recon_images, images)
# total
loss_G = loss_adv + lambda_cls * loss_cls + lambda_rec * loss_rec
history['G'].append(loss_G.item())
# update
loss_G.backward()
optimizer_G.step()
else:
history['G'].append(history['G'][-1])
'''
Save history
'''
if idx % 1000 == 0:
print('[idx : %6d] loss_G: %.5f, loss_D: %.5f \n' %(idx, history['G'][-1], history['D'][-1]))
'''
Scheduler step
'''
scheduler_G.step()
scheduler_D.step()
'''
Log
'''
time_end = datetime.now() - time_start
history['lr'].append(optimizer_G.param_groups[0]['lr'])
print('%2dM %2dS / Epoch %2d' %(*divmod(time_end.seconds, 60), epoch+1))
print('-'*20)
4. 결과
history
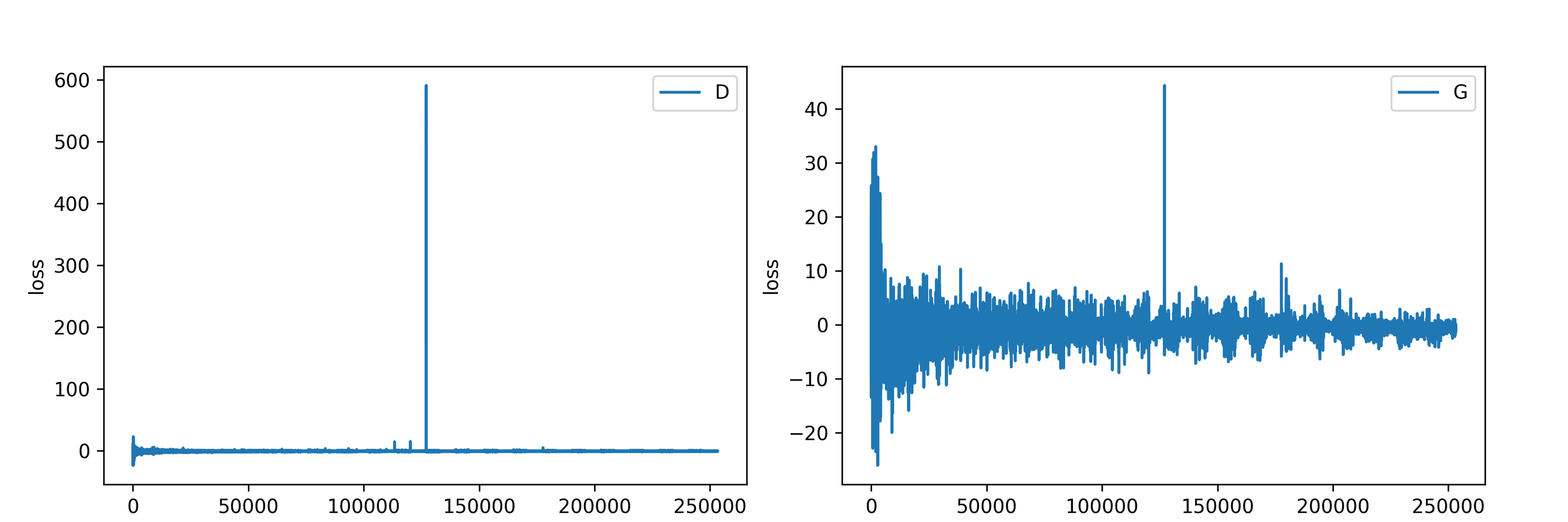
$D$와 $G$의 loss 값을 출력한 결과입니다. 중간 즈음에 $D$와 $G$ 모두 굉장히 크게 튄 값이 있는데 $D$는 그 값으로 인해 전후 값들에 대한 그래프를 보기 어려울 정도네요 ![]() 그래프의 모양을 좀 더 자세히 보기 위해 튄 값 하나만 작게 수정해보았습니다.
그래프의 모양을 좀 더 자세히 보기 위해 튄 값 하나만 작게 수정해보았습니다.
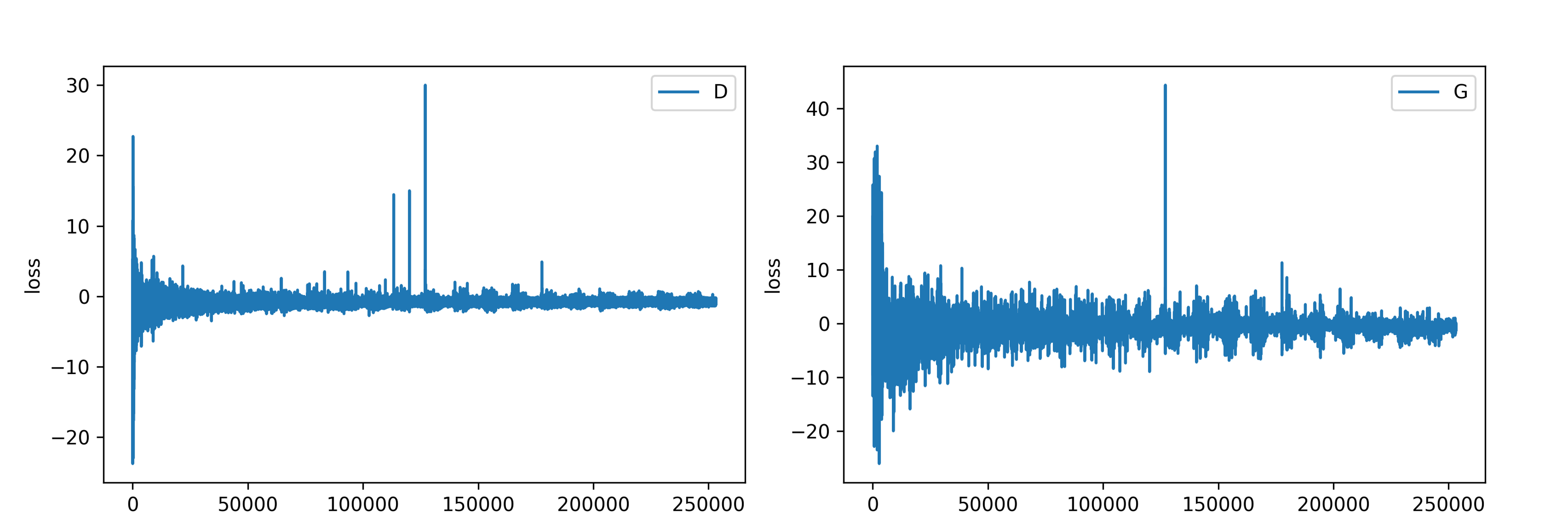
진폭의 정도가 조금씩 줄어드는 것 같긴 하지만 눈에 크게 띌 정도로 그래프 폭이 안정화되거나 하지는 않은 것 같습니다.
이미지 생성
마지막으로 모델이 생성한 결과를 확인해봅시다! CelebA와 CelebB에서 데이터를 위에서 사용했던 dataloader로 가져와 모든 속성으로 하나씩 변형해보았습니다.


언뜻 보기에는 괜찮아 보이는 결과와 전혀 괜찮지 않은 보이는 결과 둘 다 보이네요. 속성 별로 살펴본 후 이미지의 변화가 유의미한 경우와 아닌 경우를 나눠보았습니다.
성공?
성공이라 되어있지만 사실 성공이라 보기 애매한 속성들이 있어 ?를 덧붙였습니다ㅎ….

-
Black_Hair : CelebA의 데이터(남성)는 머리 색 전체가 검은 색으로 잘 변했으나 CelebB의 데이터(여성)는 머리 뿌리 부분만 검은색으로 변했으며 두 이미지 모두 수염이 생긴 것을 확인할 수 있습니다. 머리와 수염 모두를 길러 탈모를 허용하지 않는 모델이 되어버렸습니다

- Blond_Hair : 남성의 머리가 Blond로 색이 변했지만 화장이 같이 되어버렸습니다. Blond_Hair 데이터셋에는 여성의 데이터가 더 많았던게 아닐까 생각이 드는 부분이였습니다. 여성의 경우 머리색이 Blond로 변함을 볼 수 있지만 안경의 색상까지 연해져 버린 것을 확인할 수 있었습니다.
- Brown_Hair : 남성 이미지는 기존에도 갈색의 머리색을 가지고 있었지만 좀 더 짙어진 갈색으로 머리색이 변형되었고 여성 이미지는 기존 머리색이 밝다보니 남성보다는 밝은 갈색으로 머리색이 변형되었습니다.
- Mustache : 남성 이미지는 기존에도 수염이 있었으나 수염이 더 짙어졌고 여성 이미지에는 없던 수염이 생김을 확인할 수 있습니다.
- Eyeglasses : 이미지가 작아 잘 보이지 않지만 안경을 쓰고 있지 않았던 남성에게는 테가 얇은 안경이 씌워졌으며 기존에도 안경을 쓰고 있던 여성에게는 모습은 큰 변화가 없으나 이미지의 톤이 조금 어두워짐을 볼 수 있습니다.
속성에 대한 변화를 볼 수 있었으나 해당 속성뿐만 아니라 다른 속성까지 변형되는 것이 문제가 되는 부분이 보였습니다. Black_Hair 는 수염이 자라고 Blond_Hair는 화장이 되어버리네요 ![]()
Black_Hair 에는 수염을 가진 남성 데이터가, Blond_Hair 에는 화장이 된 여성 데이터가 많기 때문으로 보이는 데 데이터를 골고루 분포하도록 데이터 자체를 만지는 것 말고는 어떻게 수정해야 이 문제를 해결할 수 있을지 가늠이 가지 않네요….
실패!
완벽하게 실패한 속성들을 살펴보겠습니다.

- Bang, Wearing_Hat : 앞머리, 모자에 대한 속성으로 남성, 여성 이미지 모두 앞머리, 모자는 생성되지 않았으며 이마와 머리 부분에 노이즈처럼 무언가 칠해진 것으로 보여지는 수준입니다.
- Gray_Hair : 머리색은 변하지 않았으며 위의 Eyeglasses 속성이 같이 변하는지 남성 이미지에 안경이 씌워진 것을 볼 수 있었습니다.
- Wearing_Earrings : 귀걸이는 추가되지 않았으며 남성의 경우 화장이 된 것처럼 이미지가 변한 것을 볼 수 있습니다. 머리색을 제외하면 두 이미지 모두 위의 Blond의 결과와 유사한 것을 볼 수 있었습니다.
Bang 과 Wearing_Hat 은 머리나 이마 부분에 변화가 있어 무언가 시도한 흔적이라도 발견할 수 있는데 Gray_Hair 와 Wearing_Earrings 는 각각 위의 Eyeglasses , Blond-Hair 와 유사하게 변하는게 특이했습니다. 왜…그럴까요….??? ![]()
![]()
논문만큼 결과가 잘 나오지는 않았습니다….
결과가 논문처럼 잘 나오지 않아서 논문 구현글을 다 썼는데도 의문이 남아버렸습니다. StarGAN v2과 같은 이후 논문들을 다루면서 깨달음이 생기게 되어 코드를 수정하게 되면 수정 부분과 잘못된 부분들 정리해 글을 이어서 작성해보겠습니다 ![]()
StarGAN 논문 구현 전체 코드는 Github에서 확인하실 수 있습니다.