 solee
solee
CycleGAN(2) - 논문 구현
pix2pix의 논문 구현 글로 이전 글인 CycleGAN(1) - 논문 리뷰의 논문의 내용을 따라 구현해 Pix2Pix와 비교해보겠습니다:)
공식 코드로는 Pytorch와 Torch가 있습니다.
1. 데이터 셋
이전 글이였던 pix2pix와 성능과 비교해보고자 이전의 pix2pix에서 사용했던 CMP Facade 데이터 셋을 사용했습니다.
pix2pix 논문에서는 random jitter와 mirroring을 사용했다는 말이 있었지만 CycleGAN에는 씌여있지 않아 augmentation은 적용하지 않았으며 resize와 normalize만 적용했습니다.
class Facade(Dataset):
def __init__(self, path, transform = None):
self.filenames = glob(path + '/*.jpg')
self.transform = transform
def __getitem__(self, idx):
photoname = self.filenames[idx]
sketchname = self.filenames[idx][:-3] + 'png'
photo = Image.open(photoname).convert('RGB')
sketch = Image.open(sketchname).convert('RGB')
if self.transform:
photo = self.transform(photo)
sketch = self.transform(sketch)
return photo, sketch, (photoname, sketchname)
def __len__(self):
return len(self.filenames)
data_path = './Facade'
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset_Facade = CUHK(path = data_path,
transform=transform)
dataloader = DataLoader(dataset=dataset_Facade,
batch_size=batch_size,
shuffle=True)
데이터 셋과 모델 구조를 함께 보면 아래와 같은 그림으로 표현할 수 있습니다.
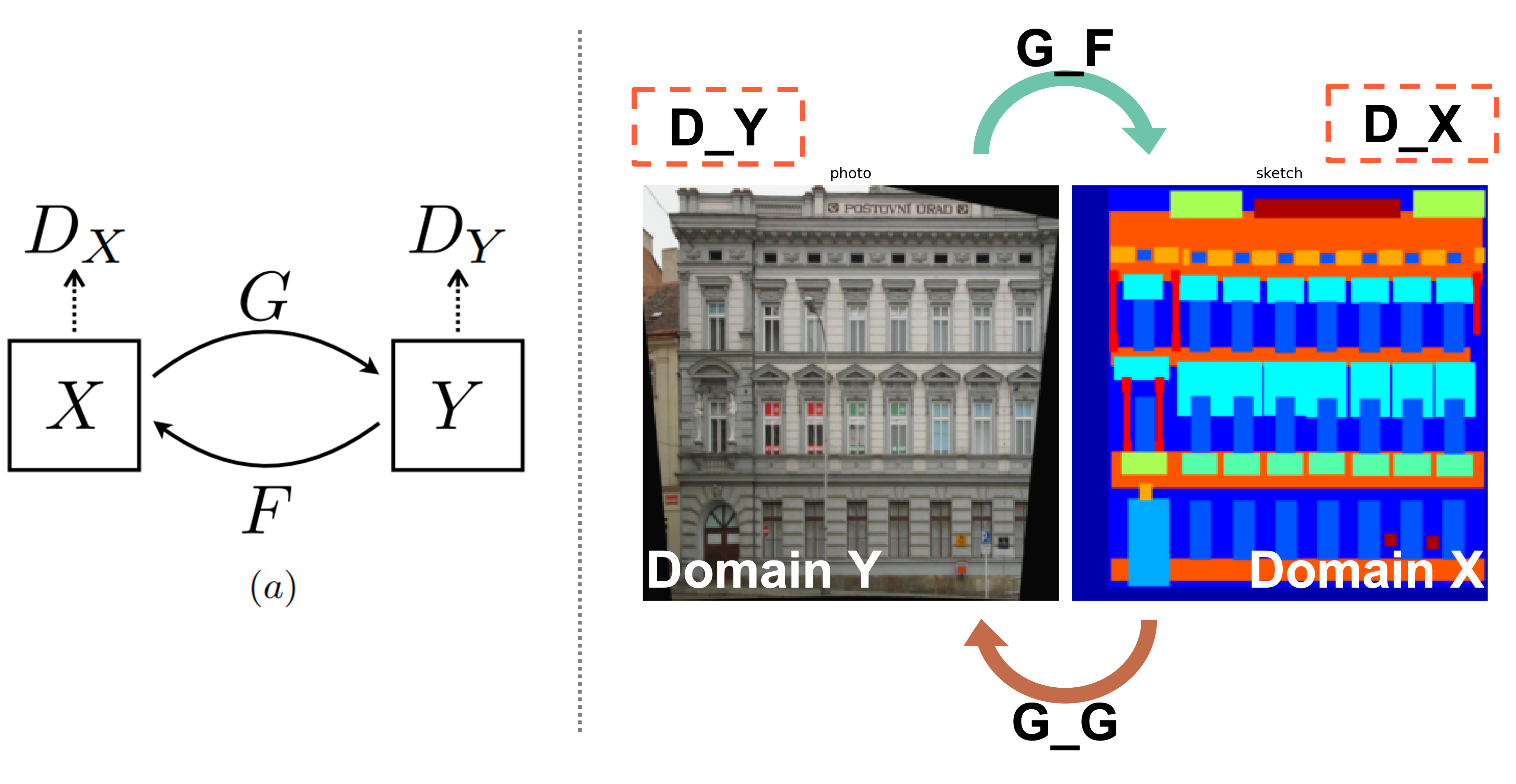
Pix2Pix와의 비교를 위해 도메인 X인 sketch를 도메인 Y인 photo로 바꾸는 Generator를 학습하는 것을 목표로 합니다. G_G, G_F는 Generator로 G_G는 도메인 X의 데이터를 도메인 Y로, G_F는 도메인 Y의 데이터를 도메인 X에 맞는 데이터로 변화시킵니다. D_X, D_Y는 Discirminator로 D_X는 실제 도메인 X의 데이터인지 생성 모델 G_F가 만든 가짜 데이터인지 판별하며 D_Y는 실제 도메인 Y의 데이터인지 생성 모델 G_G가 만든 가짜 데이터인지를 판별합니다.
2. 모델
2.1. Weight Initialize
모델의 모든 가중치는 가우시안 분포 N(0, 0.02)로 초기화합니다. 모듈의 이름을 확인해 Convolution과 관련된 모듈일 경우 nn.init.normal_함수로 N(0, 0.02)로 초기화했습니다.
def init_weight(module):
classname = module.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(module.weight, mean=0.0, std=0.02)
generator_G.apply(init_weight)
generator_F.apply(init_weight)
discriminator_X.apply(init_weight)
discriminator_Y.apply(init_weight)
2.2. Generator
Generator는 Perceptual Losses for Real-Time Style Transfer and Super-Resolution 모델을 사용합니다. 해상도에 따라 사용하는 residual block의 수가 달라지는데 128x128 크기의 이미지 데이터에서는 6개의 residual block을 사용하고 256x256 크기 또는 더 높은 해상도의 이미지 데이터에서는 9개의 residual block을 사용합니다.
모델의 구조는 $c7s1-k$, $dk$, $Rk$, $uk$로 나타낼 수 있으며 $k$는 필터의 수를 나타냅니다. 명칭 별 구조는 아래와 같으며 각 Convolution에는 padding이 적용되는데 artifact를 줄이기 위해 Reflection padding을 사용했다 합니다.
- $c7s1-k$ : k filter와 1 stride를 가진 7x7 Convolution - InstanceNorm - ReLU
- $dk$ : k filter와 2 stride를 가진 3x3 Convolution - InstanceNorm - ReLU
- $Rk$ : [k filter를 가진 3x3 Convolution - InstanceNorm - ReLU] x 2
- $uk$ : k filter와 1/2 stride를 가진 3x3 fractional strided Convolution - InstanceNorm - ReLU
Facade 데이터 셋은 256x256으로 Resize해 사용하므로 저는 9개의 Residual block(Rk)를 사용하며 9 residual block으로 이루어진 네트워크는 $c7s1-64, d128, d256, R256 * 9, u128, u64, c7s1-3$입니다. 해당 구조를 아래 코드로 나타낼 수 있습니다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
XK(3, 64, name='ck'),
XK(64, 128, name='dk'),
XK(128, 256, name='dk'),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
Residual(256, 256),
XK(256, 128, name='uk'),
XK(128, 64, name='uk'),
XK(64, 3, name='ck', drop=True),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
9 residual block으로 이루어진 네트워크인 $c7s1-64, d128, d256, R256 * 9, u128, u64, c7s1-3$인 Generator입니다. XK(64, 3, name='ck', drop=True)에만 drop 인자가 있는데 마지막 레이어에서 InstanceNorm과 ReLU가 사용되면 생기는 artifact를 방지하기 위해 인자로 해당 레이어에서는 Convolution만이 모델에 추가되어야 해야하므로 이를 위해 drop인자를 사용했습니다. 마지막으로는 이미지 생성을 위한 nn.Tanh()를 추가합니다.
class Residual(nn.Module):
def __init__(self, in_feature, out_feature):
super(Residual, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_feature, out_feature, kernel_size=3, padding=1, padding_mode='reflect'),
nn.InstanceNorm2d(out_feature),
nn.ReLU(),
nn.Conv2d(in_feature, out_feature, kernel_size=3, padding=1, padding_mode='reflect'),
nn.InstanceNorm2d(out_feature),
nn.ReLU()
)
def forward(self, x):
return x + self.model(x)
Residual block에 해당하는 코드입니다. $RK$는 3x3 Convolution-InstanceNorm-ReLU 가 2번 반복되는 모양입니다. 입력 값으로 들어오는 x와 Resiaudal block의 출력인 self.model(x)의 값을 더해 최종 출력 값으로 사용해 gradient vanishing 문제를 완화할 수 있는 것이 특징입니다.
class XK(nn.Module):
def __init__(self, in_feature, out_feature, name, drop=False):
super(XK, self).__init__()
if name == 'ck':
conv = nn.Conv2d(in_feature, out_feature, kernel_size=7, stride=1, padding=3, padding_mode='reflect')
elif name == 'dk':
conv = nn.Conv2d(in_feature, out_feature, kernel_size=3, stride=2, padding=1, padding_mode='reflect')
elif name == 'uk':
conv = nn.ConvTranspose2d(in_feature, out_feature, kernel_size=3, stride=2, padding=1, output_padding=1)
else:
raise Exception('Check name')
norm = nn.InstanceNorm2d(out_feature)
relu = nn.ReLU()
model = [conv, norm, relu]
if drop:
model = [conv]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
Rsidual block인 ‘RK’를 제외한 각 구조 명칭 별로 대응되도록 XK 클래스를 만들었습니다. 모든 구조에서 InstanceNorm과 ReLU가 사용되는 것은 동일하므로 name으로 넘어오는 구조 명에 따라 사용되는 Convolution만 변경됩니다. 또한 위에서 언급했듯 마지막 레이어에서 InstanceNorm과 ReLU가 사용되면 생기는 artifact를 방지하기 위해 마지막 레이어에서 drop 인자가 넘어오게 되면 Convolution만이 모델에 추가되도록 구현했습니다.
2.3. Discriminator
Discriminator는 Pix2Pix와 마찬가지로 70x70 PatchGAN을 사용합니다. 이전 글인 Pix2Pix code에서 사용한 Discriminator와 같은 Discriminator를 사용했습니다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(512, 1, kernel_size=4, stride=4, dilation=3),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
3. 학습
CycleGAN은 학습 안정화를 위해 3가지 방법을 사용합니다. Buffer, Scheduler, loss 변화로 사용 목적과 함께 소개해드리겠습니다.
3.1. Buffer
Pix2Pix를 포함한 이전 모델에서 판별 모델의 업데이트는 minibatch의 이미지에서만 이루어졌습니다. CycleGAN은 SimGAN의 Buffer를 사용합니다.
Discriminator(D)를 학습시키면서 D는 최근 생성된 이미지들에 집중하는 경향이 생기거나 G가 D를 잘 속일 수 있는 artifact를 발견해 artifact를 계속 생성하는 문제가 발생할 수 있습니다. Buffer는 이를 해결하기 위해 생성된 이미지 히스토리를 사용해 판별 모델을 업데이트하는 방법으로 adversarial 학습의 안정성을 향상시킬 수 있습니다.
SimGAN에서는 G가 생성한 fake 이미지를 D가 학습할 때 buffer를 사용합니다. minibatch 크기를 b라 했을 때 G로 부터 생성된 이미지에서 b/2, 버퍼에서 b/2만큼 이미지를 샘플링해 판별 모델 업데이트에 사용합니다. 업데이트 이후 버퍼 내부 이미지들 중 b/2 만큼 샘플링 해 새로 생성된 이미지로 무작위 교체합니다.
CycleGAN의 경우 mini batch가 1이므로 b/2만큼 버퍼에서 샘플링하고 b/2만큼 생성된 이미지에서 샘플링하는 것을 할 수 없어 생성 모델에서 생성된 이미지 1장과 버퍼에서 무작위로 1장을 추출해 D를 학습하도록 했습니다. 학습 후 버퍼에 이미지 장수가 50장 미만이라면 새롭게 생성했던 이미지 1장을 버퍼에 넣고 50장 이상이라면 무작위로 교체하도록 했습니다. 50장은 버퍼의 크기로 논문 4.Implementation에 언급된 크기를 사용했습니다.
class Buffer():
def __init__(self):
self.history = []
def insert(self, x):
if len(self.history) < 50:
self.history.append(x)
else:
idx = int(random() * 50)
self.history[idx] = x
def sampling(self, image):
if len(self.history) == 0:
return image
idx = int(random() * len(self.history))
return torch.cat((image, self.history[idx]), dim=0)
def __len__(self):
return len(self.history)
3.2. Scheduler
learning rate는 0.0002로 첫 100 epoch 동안 유지되며 이후 100 epoch 동안 0 까지 linear하게 learning rate를 줄어들게 한다고 합니다. scheduler를 사용해 learning rate를 관리할 수 있습니다. 다양한 scheduler가 있지만 지정한 함수에 따라 자유롭게 lr를 조절할 수 있는게 LambdaLR을 사용했습니다.
scheduler_lambda = lambda epoch: 1.0 - max(0, epoch - 99) / float(100)
scheduler_G_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G_G, lr_lambda=scheduler_lambda)
scheduler_G_F = torch.optim.lr_scheduler.LambdaLR(optimizer_G_F, lr_lambda=scheduler_lambda)
scheduler_D_X = torch.optim.lr_scheduler.LambdaLR(optimizer_D_X, lr_lambda=scheduler_lambda)
scheduler_D_Y = torch.optim.lr_scheduler.LambdaLR(optimizer_D_Y, lr_lambda=scheduler_lambda)
lambdaLR을 사용하기 위해서는 lr에 적용할 함수 또는 바뀔 lr 값에 대한 리스트를 입력으로 주어야 합니다. scheduler_lambda를 만들어 함수로 넣어주었습니다. 100 epoch 이후 lr 값에 lr/100씩 값을 감소시켜 점점 lr 값이 0이 되도록 작아지게 구현합니다.

scheduler에 의해 변화된 lr 값을 epoch에 따라 기록한 결과 이미지입니다. 초기 lr 값인 0.0002로 100 epoch 간 유지되다 이후 점점 줄어드는 것을 확인할 수 있습니다.
3.3. GAN Loss
GAN loss는 sigmoid cross entropy loss function을 사용했었습니다. CycleGAN에서 GAN loss로는 LSGAN에서 소개된 Least Square Loss를 사용합니다.
G가 생성한 가짜 이미지를 D가 진짜라고 판별했다 하더라도 다양한 이유로 진짜 이미지와의 차이가 커 생성 이미지의 퀄리티가 떨어질 수 있습니다. D의 학습이 부족했을 수도 있고 G가 D를 잘 속이는 artifact를 생성했을 가능성도 있습니다. 이미지 퀄리티 자체를 least square를 이용해 높이고 실제 데이터 분포와 가까운 이미지를 생성하는 것이 목표입니다. 또한 sigmoid cross entropy loss와는 달리 least square loss를 오직 한 점에서만 최소값을 갖기 때문에 학습이 안정적이라는 장점이 있습니다.
\[\min_D V _{LSGAN}(D) = \frac{1}{2}\mathbb{E} _{x \sim p _{data}(x)}[(D(x)-b)^2] + \frac{1}{2}\mathbb{E} _{z \sim p_z(z)}[(D(G(z))-a)^2]\] \[\min_G V _{LSGAN}(G) \frac{1}{2}\mathbb{E} _{z \sim p_z(z)}[(D(G(z))-c)^2]\]첫번째 수식에서 a는 G가 생성한 가짜 데이터 라벨, b는 실제 데이터 라벨을 의미합니다. 첫번째 수식은 D의 학습에 대한 식으로 실제 데이터인 b(1)이 입력된다면 1로 결과를 출력하고 가짜 데이터인 a(0)이 입력된다면 0으로 결과를 출력해 식을 최소화하도록 합니다. 두번째 수식에서 c는 G가 생성한 가짜 데이터로 D가 실제라고 믿기를 바라는 데이터를 의미합니다. G는 D가 속을 수 있도록 실제 데이터이길 바라는 c(1)와 D의 결과가 최대한 1에 가깝게 출력되도록 식을 최소화합니다. 수식이 Mean squared Loss와 모양이 같은 것을 볼 수 있으며 따라서 코드로는 nn.MSELoss()를 사용해 구현했습니다. 학습 코드는 아래와 같습니다.
loss_lse = nn.MSELoss().cuda()
loss_l1 = nn.L1Loss().cuda()
for epoch in range(n_epochs):
time_start = datetime.now()
history_loss = [0, 0, 0]
generator_G.train()
for photos, sketches, _ in dataloader:
photos = photos.cuda()
sketches = sketches.cuda()
'''
Discriminator
'''
optimizer_D_X.zero_grad()
optimizer_D_Y.zero_grad()
# generate fake
fake_X = generator_F(photos).detach() # buffer로 들어가 다시 사용될 수 있으므로 detach해 추적을 막아주어야 한다.
fake_Y = generator_G(sketches).detach()
# classify real data
d_real_X = discriminator_X(sketches)
d_real_Y = discriminator_Y(photos)
# classify fake data
d_fake_X = discriminator_X(buffer_X.sampling(fake_X))
d_fake_Y = discriminator_Y(buffer_Y.sampling(fake_Y))
# loss
loss_X = (loss_lse(d_real_X, ones) + loss_lse(d_fake_X, zeros)) / 2
loss_Y = (loss_lse(d_real_Y, ones) + loss_lse(d_fake_Y, zeros)) / 2
history_loss[1] += loss_X.item()
history_loss[2] += loss_Y.item()
# buffer insert
buffer_X.insert(fake_X)
buffer_Y.insert(fake_Y)
# update
loss_X.backward()
loss_Y.backward()
optimizer_D_X.step()
optimizer_D_Y.step()
'''
Generator
'''
optimizer_G_G.zero_grad()
optimizer_G_F.zero_grad()
# generate real
fake_Y = generator_G(sketches)
fake_X = generator_F(photos)
# classify fake
d_fake_X = discriminator_X(fake_X)
d_fake_Y = discriminator_Y(fake_Y)
# loss(gan)
loss_gan = (loss_lse(d_fake_X, ones) + loss_lse(d_fake_Y, ones))
# loss(cycle)
F_G_X = generator_F(fake_Y) # for forward cyc
G_F_Y = generator_G(fake_X) # for backward cyc
loss_cyc = loss_l1(sketches, F_G_X) + loss_l1(photos, G_F_Y)
if identity is True:
pass
else:
loss_G = loss_gan + loss_cyc * lambda_cyc
history_loss[0] += loss_G.item()
# update
loss_G.backward()
optimizer_G_G.step()
optimizer_G_F.step()
'''
scheduler step
'''
scheduler_D_X.step()
scheduler_D_Y.step()
scheduler_G_G.step()
scheduler_G_F.step()
'''
History
'''
time_end = datetime.now() - time_start
loss = [history_loss[0]/len_loader, history_loss[1]/len_loader, history_loss[2]/len_loader]
history['G'].append(loss[0])
history['D_X'].append(loss[1])
history['D_Y'].append(loss[2])
history_lr.append(optimizer_G_G.param_groups[0]["lr"])
generator_G.eval()
with torch.no_grad():
test = generator_G(sketch)[0].detach().cpu()
test = transforms.functional.to_pil_image(0.5 * test + 0.5)
history_image.append(test)
test.save('./history/test/' + str(epoch).zfill(3) + '.png')
print('%2dM %2dS / Epoch %2d' %(*divmod(time_end.seconds, 60), (epoch+1)))
print('loss_G: %.5f, loss_D_X: %.5f, loss_D_Y: %.5f' %(loss[0], loss[1], loss[2]))
Jaejun Yoo님의 초짜 대학원생의 입장에서 이해하는 LSGAN에서 LSGAN의 장점에 대해 자세한 설명이 있으니 함께 보시는 걸 추천드립니다 ![]()
4. 결과
4.1. history
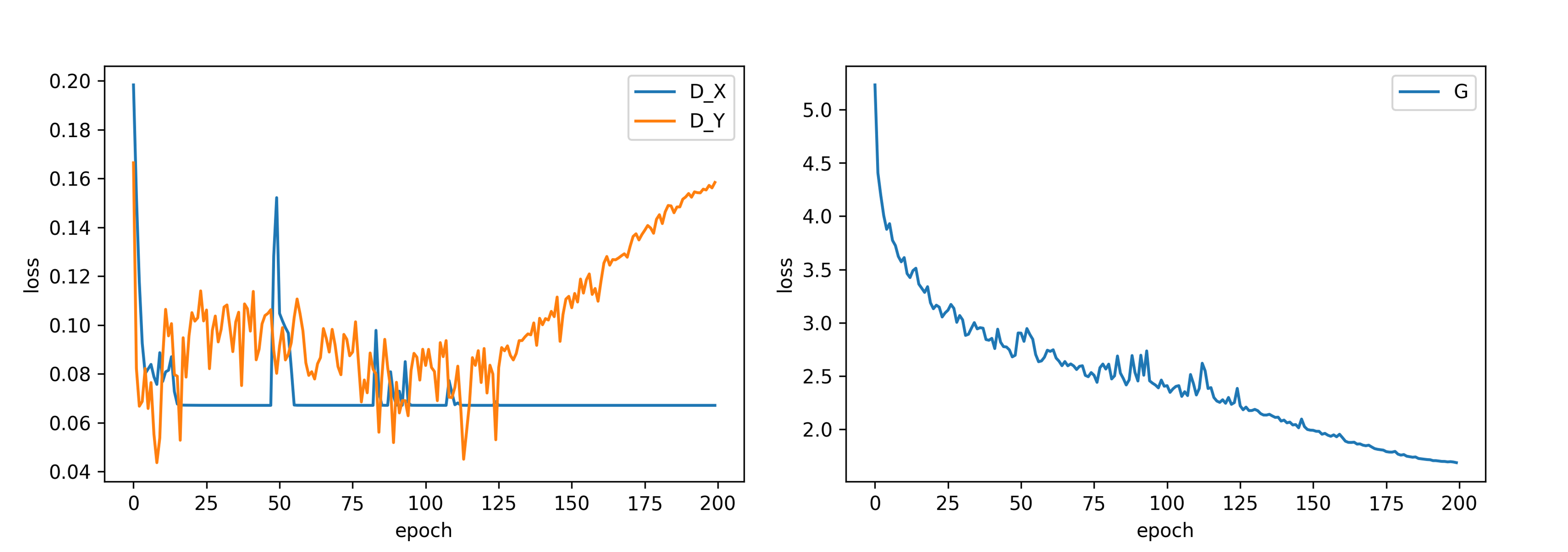
학습에 따라 loss 변화를 그래프로 나타낸 결과입니다. Generator의 loss는 Epoch에 따라 내려가는 걸 볼 수 있는데 100 epoch 즈음 변동이 커지다 scheduler로 인해 lr이 줄어들며 loss 변화가 안정적으로 바뀌며 학습이 진행되는 것을 확인할 수 있습니다.
반면 D는 D_X와 D_Y의 변화가 크게 다르네요…? 도메인 Y가 실제 사진(photo) 데이터인데 실제 사진 데이터는 G_G가 가짜 이미지를 현실적으로 잘 생성해 D_Y가 G_G에게 상대적으로 잘 속는 것에 반해 라벨(sketch) 데이터는 G_F가 상대적으로 만들어 내는 능력이 떨어져 D_X를 속이지 못하는 것으로 보입니다.
G_G가 200epoch 동안 생성한 이미지 히스토리입니다. 초반에는 과거 흑백 영화 같은 이미지에서 색이 조금 입혀지더니 50~70 epoch 즈음부터 창문과 창틀 등의 이미지의 디테일이 생기는 걸 볼 수 있습니다. D_Y를 속이기 시작했던 130 epoch 즈음부터는 좀 더 현실적인 이미지를 생성한다 느껴졌습니다.
4.2. CycleGAN vs Pix2Pix

논문에서는 Pix2Pix의 결과가 더 좋았으며 Pix2Pix 페어 데이터를 사용하나 CycleGAN은 페어 데이터를 사용하지 않는 것의 차이가 있으니 페어 데이터를 사용하지 않고 Pix2Pix를 얼마만큼 따라잡을 수 있는 지를 봐야한다 했었습니다. 위의 결과에서도 언뜻 보기에는 Pix2Pix가 더 괜찮아 보이기는 합니다. 하지만 창문 밖 난관이나 건물 끝 외관 등의 디테일한 부분에서 Pix2Pix는 흐릿하게 blur 처리한 것처럼 보이지만 CycleGAN은 상대적으로 blur함이 덜하고 어떻게든 라벨을 표현해 디테일한 부분은 오히려 CycleGAN이 상대적으로 더 잘 표현한 것처럼 보이네요.
사용한 cmp_x0006, cmp_x0220 데이터는 학습에 사용하지 않은 CMP facade DB extended에서 가져온 사진으로 아직까지는 학습하지 않은 사진들에 대해 general하게 사실적인 이미지를 잘 생성했다 보기는 어려운 것 같습니다. 학습 데이터셋에 높이가 다른 두 건물이 연결된 경우가 별로 없었던지 cmp_x0220의 경우 두 건물이 어색하게 건물이 연결되어 있고 좌측의 건물은 꼭대기 층 자체가 명확하지 않은 걸 확인할 수 있었습니다.아직 갈 길이 멀어 보입니다 ![]()
CycleGAN 코드 글은 여기서 끝입니다. 봐주셔서 감사합니다:)
드디어 Supervised 모델에서 Unsupervised 모델로 넘어왔습니다!! 이제 멀티 도메인 논문이나 Few shot 논문으로 넘어가볼까 합니다. 점점 영역을 넓혀가는 것 같아서 뿌듯해지네요 히히. 열심히 해보겠습니다. ![]()
CycleGAN의 전체 코드는 github에서 확인하실 수 있습니다!