 solee
solee
Pix2Pix(2) - 논문 구현
pix2pix의 논문 구현 글로 이전 글인 Pix2Pix(1) - 논문 리뷰의 논문의 내용을 따라 구현해 보았습니다. 가능한 작은 데이터셋으로 논문을 구현하고 작은 데이터셋으로 얼만큼의 성능이 나오는지 확인해보고자 합니다:)
공식 코드로는 논문에 언급된 phillipi/pix2pix가 있으나 lua로 작성되어 있으며 PyTorch로 작성된 코드로는 Pix2Pix와 CycleGAN을 구현한 junyanz의 pytorch-CycleGAN-and-pix2pix가 있습니다.
1. 데이터 셋
논문에서는 총 8개의 데이터셋을 사용합니다. 이중에서 10,000장 이하의 작은 데이터셋은 3개가 있습니다.
- Cityscapes labels $\rightarrow$ photo / 2975장
- Architectural labels $\rightarrow$ photo / 400장
- Maps $\leftrightarrow$ aerial photograph / 1096장
3가지 데이터셋 모두 random jitter와 mirroring을 사용해 200 epoch만큼 학습했다고 합니다. random jitter와 mirroring 모두 data augmentation을 위해 사용합니다.
random jitter로는 이미지를 286 x 286으로 resize한 다음 256 x 256으로 random cropping해 사용하며 issues를 보니 286 x 286으로 지정한 특별한 이유는 없다고 답변이 되어 있었습니다. random crop을 위해 원하는 크기보다 적당히 큰 정도면 될 것 같아요! mirroring은 flip을 의미합니다. augmentation의 대표적인 방법으로 데이터셋에 따라 horizontal flip 또는 vertical flip을 추가했다 이해했습니다.

CMP Facade Database의 예시입니다.
다양한 건축 양식을 가진 건물 사진과 창문, 기둥과 같은 12개의 클래스로 라벨링된 라벨링 이미지가 페어를 이루고 있습니다.
저는 위의 3개의 데이터셋 중 2. Architectural labels $\rightarrow$ photo를 사용해 모델을 구현하고 400장이라는 적은 데이터 셋만으로 합리적인 결과를 생성할 수 있는지 확인해보겠습니다. 데이터셋은 CMP Facade Database에서 다운받을 수 있습니다.
Base 데이터셋과 Extended 데이터셋이 있는데 Base 데이터셋은 378장이고 Extended 데이터셋은 228장으로 이루어져있으며 논문은 400장을 사용했다 합니다. 어떻게 섞어서 400장이 된건지는 적혀있지 않아 저는 Base 데이터셋만을 이용해 학습하고 최종 모델 성능을 확인하기 위해 학습에 사용되지 않은 Extended 데이터셋에서 2~3장 정도를 뽑아 테스트해보겠습니다.
# 이후 변경되는 코드입니다. 잘못된 부분을 찾으신 분께는 진심의 박수를 드립니다.
# 저는 이걸 못 찾아서 오랫동안 헤메었거든요....ㅠ
class Facade(Dataset):
def __init__(self, path, transform = None):
self.filenames = glob(path + '/*.jpg')
self.transform = transform
def __getitem__(self, idx):
photoname = self.filenames[idx]
sketchname = self.filenames[idx][:-3] + 'png'
photo = Image.open(photoname).convert('RGB')
sketch = Image.open(sketchname).convert('RGB')
if self.transform:
photo = self.transform(photo)
sketch = self.transform(sketch)
return photo, sketch, (photoname, sketchname)
def __len__(self):
return len(self.filenames)
transform = transforms.Compose([
transforms.Resize((286, 286)),
transforms.RandomCrop((256, 256)), # Random jitter
transforms.RandomHorizontalFlip(0.5), # Mirroring
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset_Facade = Facade(path = data_path,
transform=transform)
dataloader = DataLoader(dataset=dataset_Facade,
batch_size=batch_size,
shuffle=True)
Random jitter를 위해 이미지를 (286x286)으로 Resize 한 후 (256x256)으로 RandomCrop을 적용했습니다. 그리고 Mirroring을 위한 RandomHorizontalFlip을 transforms에 추가해 코드를 구현했습니다.
Generator의 마지막 activation은 tanh로 출력 범위가 (-1, 1)이므로 Normalize의 채널 별 mean과 std를 모두 0.5로 설정해 이미지의 범위를 [-1, 1]로 맞춰주었습니다.
2. 모델
Generator와 Discriminator의 자세한 구조는 논문의 Appendix에서 확인할 수 있습니다.
논문에서는 $Ck$와 $CDk$로 모델의 구조를 설명합니다.
$Ck$는 k개의 필터를 가진 Convolution-BatchNorm-ReLU 레이어를 의미하고 $CDk$는 k개의 필터를 가진 Convolution-BatchNorm-Dropout-ReLU 레이어를 의미하며 이때 dropout rate는 50%입니다.
모든 convolution들은 stride 값은 2이고 4x4의 filter를 사용합니다. convolution을 통해 Encoder(Generator)와 Discriminator에서 convolution으로 downsample되는 지수는 2이고 Decoder(Generator)에서 convolution으로 upsample되는 지수 또한 2입니다.
convolution을 통해 downsample된다는 것은 이미지의 크기를 줄이는 것은 말하며 이때 downsample 지수가 2이므로 Encoder와 discriminator에서 이미지가 convolution을 통과할 때마다 이미지의 크기는 절반이 됩니다. upsample 또한 지수가 2이므로 Decoder에서 이미지가 convolution을 통과하면 이미지의 크기는 2배가 되어야 합니다. 더 자세한 내용은 아래의 코드와 함께 확인해보아요!
2.1. Generator
Generator는 Encoder-Decoder 구조로 다음과 같이 이루어져 있습니다.
encoder : $C64-C128-C256-C512-C512-C512-C512-C512$
decoder : $CD512-CD512-CD512-CD512-C256-C128-C64$
Generator에 $Ck$와 $CDk$ 모두 사용되므로 dropout이 적용되는 곳과 적용되지 않는 곳, skip connection으로 합쳐져야 하는 부분 등을 편하게 적용시켜 줄 새로운 BlockCK라는 클래스를 작성했습니다.
class BlockCK(nn.Module):
def __init__(self, in_ch, out_ch, is_encoder=True, is_batchnorm=True, is_dropout=False):
super(BlockCK, self).__init__()
self.is_encoder = is_encoder
if is_encoder:
conv = nn.Conv2d(in_ch, out_ch, kernel_size=4, stride=2, padding=1)
relu = nn.LeakyReLU(0.2)
else:
conv = nn.ConvTranspose2d(in_ch, out_ch, kernel_size=4, stride=2, padding=1)
relu = nn.ReLU()
batchnorm = nn.InstanceNorm2d(out_ch)
dropout = nn.Dropout(0.5)
model = [conv]
if is_batchnorm:
model += [batchnorm]
if is_dropout:
model += [dropout]
model += [relu]
self.model = nn.Sequential(*model)
def forward(self, x, skip=None):
if self.is_encoder:
return self.model(x)
else:
return torch.cat((self.model(x), skip), 1)
Convolution-BatchNorm-ReLU인 $Ck$ 구조와 Convolution-BatchNorm-Dropout-ReLU인 $CDk$ 구조의 가장 큰 차이는 dropout 여부로 is_dropout 인자를 통해 넣을지 말지 정할 수 있도록 구현했습니다. 또한 Encoder의 첫번째 레이어인 $C64$에는 batchnorm이 적용되지 않는다 논문에 언급되어 있어 is_batchnorm 인자를 통해 유연하게 대응할 수 있도록 구현했습니다.
또한 Encoder의 모든 ReLU는 slope가 0.2로 설정된 LeakyReLU이고 decoder는 LeakyReLU가 아닌 ReLU이기 때문에 is_encoder 인자를 통해 Encoder 에 해당하는 경우 conv + LeakyReLU를 decoder에 해당하는 경우 ConvTranspose + ReLU를 사용하도록 합니다.
기존 Unet은 downsampling을 하기 위해 maxpooling을 사용해 이미지 크기를 절반으로 줄이지만 Pix2Pix에서는 4x4 Convolution을 사용하므로 이미지 크기가 절반으로 줄 수 있도록 stride=2, padding=1 옵션을 사용해 convolution을 통과할 때마다 이미지 크기가 절반이 되도록 조절했습니다.
upsampling은 ConvTranspose(transposed convolution)를 사용합니다. convolution이 이미지 크기를 줄이고 채널 수를 조절하는 것에 주로 사용된다면 ConvTranspose 이미지 크기를 늘리고 채널 수를 조절하는 것에 사용됩니다. ConvTranspose은 up convolution, deconvolution, fractionally strided convolution 등 다양하게 불리지만 deconvolution은 convolution의 연산을 역으로 돌리는 역함수와 같은 연산으로 사실 다른 연산이라고 하니 deconvolution은 틀린 명명법이라는 것을 주의하면 될 것 같습니다.
마지막으로 Generator는 Unet의 구조를 사용하므로 Encoder의 레이어 $i$ 와 Decoder의 레이어 $n-i$ 사이 skip connection을 연결해야 합니다. 따라서 forward에서 is_encoder의 인자를 통해 Decoder 부분임을 확인한 후 skip connection으로 넘어온 인자와 연산 결과를 합쳐 skip connection을 구현했습니다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.down_1_C64 = BlockCK(3, 64, is_batchnorm=False)
self.down_2_C128 = BlockCK(64, 128)
self.down_3_C256 = BlockCK(128, 256)
self.down_4_C512 = BlockCK(256, 512)
self.down_5_C512 = BlockCK(512, 512)
self.down_6_C512 = BlockCK(512, 512)
self.down_7_C512 = BlockCK(512, 512)
self.down_8_C512 = BlockCK(512, 512, is_batchnorm=False)
self.up_7_CD512 = BlockCK(512, 512, is_encoder=False, is_dropout=True)
self.up_6_CD512 = BlockCK(1024, 512, is_encoder=False, is_dropout=True)
self.up_5_CD512 = BlockCK(1024, 512, is_encoder=False, is_dropout=True)
self.up_4_CD512 = BlockCK(1024, 512, is_encoder=False)
self.up_3_C256 = BlockCK(1024, 256, is_encoder=False)
self.up_2_C128 = BlockCK(512, 128, is_encoder=False)
self.up_1_C64 = BlockCK(256, 64, is_encoder=False)
self.conv = nn.ConvTranspose2d(128, 3, kernel_size=4, stride=2, padding=1)
self.tan = nn.Tanh()
def forward(self, x):
down_1 = self.down_1_C64(x)
down_2 = self.down_2_C128(down_1)
down_3 = self.down_3_C256(down_2)
down_4 = self.down_4_C512(down_3)
down_5 = self.down_5_C512(down_4)
down_6 = self.down_6_C512(down_5)
down_7 = self.down_7_C512(down_6)
down_8 = self.down_8_C512(down_7)
up_7 = self.up_7_CD512(down_8, skip=down_7)
up_6 = self.up_6_CD512(up_7, skip=down_6)
up_5 = self.up_5_CD512(up_6, skip=down_5)
up_4 = self.up_4_CD512(up_5, skip=down_4)
up_3 = self.up_3_C256(up_4, skip=down_3)
up_2 = self.up_2_C128(up_3, skip=down_2)
up_1 = self.up_1_C64(up_2, skip=down_1)
conv = self.conv(up_1)
tan = self.tan(conv)
return tan
위에서 구현한 BlockCK 모듈을 이용해 구현한 Generator입니다. 원래는 self.down_8_C512 에도 batchnorm이 사용되는 것으로 논문에 나와있지만 instance normalization의 경우 처리할 map의 (width x height)가 1 초과일 때만 가능합니다. 즉, (1x1)인 경우 instance normalize를 적용할 수 없습니다. 제가 구현한 Generator의 경우 256x256 이미지 크기 기준으로 이 Generator에서 연산을 할 경우 self.down_7_C512의 feature map의 크기가 (512x1x1) 로 instance normalization을 적용할 수 없어 self.down_8_C512의 인자에서 is_batchnorm=False를 통해 normalization을 적용하지 않도록 변경하였습니다.
self.up_1_C64 연산 이후에는 채널 수를 3으로 맞추고 이미지의 크기를 256x256으로 맞추기 위한 ConvTranspose가 적용된 후 tanh activation을 연결해 픽셀 별 출력 범위가 (-1, 1)로 변환된 이미지를 생성합니다.
2.2. Discriminator
discriminator의 구조는 receptive field 크기 별로 조금씩 다릅니다.
70 x 70 : $C64 - C128 - C256 - C512$
1 x 1 : $C64 - C128$
16 x 16 : $C64 - C128$
286 x 286 : $C64 - C128 - C256 - C512 - C512 - C512$
Discriminator의 최종 feature map 크기가 receptive field가 됩니다. 논문에서 가장 좋은 점수를 받은 receptive field 크기는 16 x 16과 70 x 70이며 저는 70 x 70으로 구현해보았습니다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(6, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(512, 1, kernel_size=4, stride=4, dilation=3),
nn.Sigmoid()
)
def forward(self, x, origin):
return self.model(torch.cat((x, origin), 1))
70 x 70의 구조인 $C64 - C128 - C256 - C512$ 이후 마지막 convolution을 ConvTranspose를 사용해 receptive field 크기가 70 x 70이 되도록 맞추었습니다. 마지막으로는 sigmoid activation을 적용해 (0, 1) 범위의 값을 출력할 수 있도록 맞춰줍니다.
추가로 첫번째 Conv2d의 in_channel 값이 이미지 채널 값인 3이 아닌 6인 이유는 conditional gan을 사용하기 때문에 입력이 될 이미지와 조건이 되는 이미지 2장을 받아 합치기 때문에 두 이미지의 채널을 합쳐 3 + 3 = 6이 되기 때문입니다.
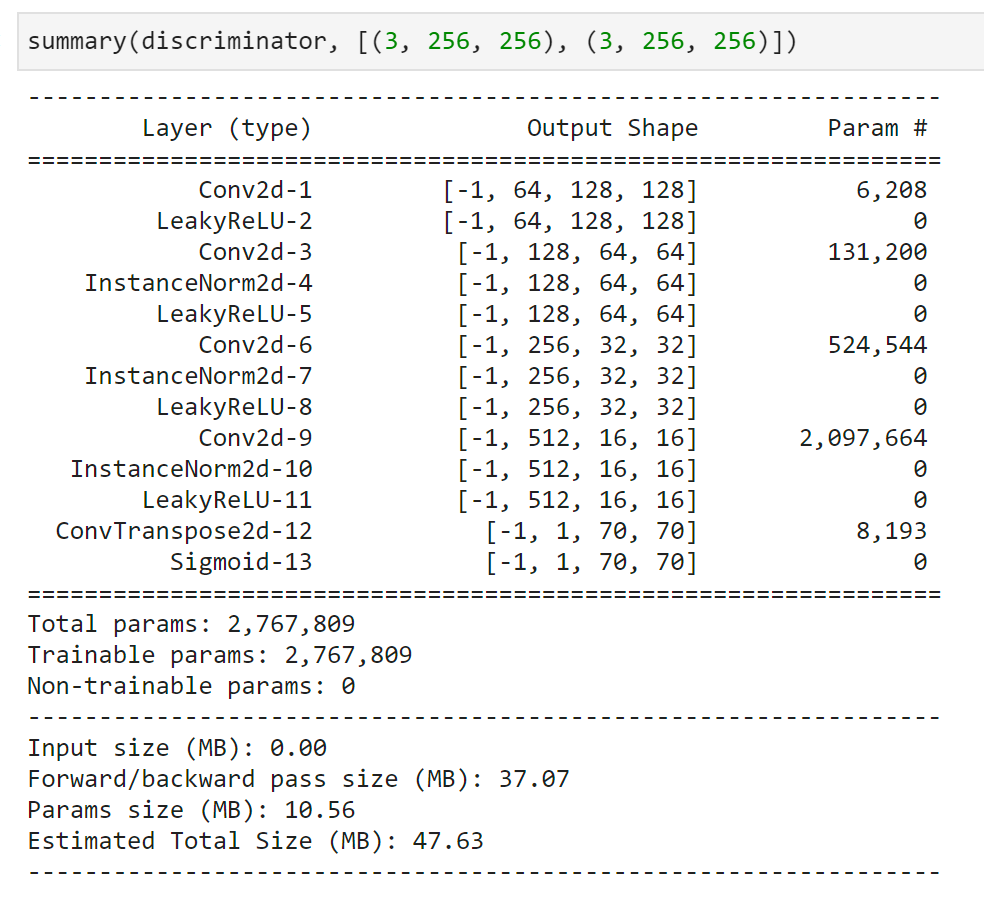
이미지 2장을 Discriminator에 입력했을 때 70 x 70의 receptive field가 된다는 것을 summary로 확인했습니다.
2.3. Weight Initialize
weight의 mean은 0으로, std는 0.02인 Gaussian distribution(=normal distribution)으로 초기화했다고 합니다. 가중치 초기화를 위한 함수를 만들고 nn.Module.apply 함수를 이용해 모델에 적용해주었습니다.
def init_weight(module):
classname = module.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(module.weight, mean=0.0, std=0.02)
generator = Generator()
discriminator = Discriminator()
generator.apply(init_weight)
discriminator.apply(init_weight)
3. 추가 설정 및 학습
3.1. 추가 설정
optimizer는 Generator와 Distriminator 모두 Adam을 사용합니다. 다만 DCGAN에서 제안한 것처럼 beta1 = 0.5, beta2 = 0.999를 사용한 ADAM을 사용하며 learning rate = 0.0002로 설정합니다.
batch size는 데이터셋 별로 차이가 있으나 CMP Facade DB의 경우 batch size로 1을 사용했다 나와있어 저 또한 batch size를 1로 설정했으며 epoch 또한 논문과 같은 200 epoch으로 설정했습니다.
loss는 gan loss와 l1 loss로 각각 torch.nn.BCELoss와 torch.nn.L1loss를 사용했습니다. ones와 zeros는 Discriminator의 receptive field 크기와 같은 크기로 만든 후 이후 loss 계산에 사용합니다. 업데이트해야 하는 변수가 아니므로 requires_grad = False로 설정해주었습니다.
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(beta1, beta2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, beta2))
loss_gan = torch.nn.BCELoss()
loss_l1 = torch.nn.L1Loss()
ones = torch.ones(batch_size, 1, 70, 70).cuda()
ones.requires_grad = False
zeros = torch.zeros(batch_size, 1, 70, 70).cuda()
zeros.requires_grad = False
3.2. 학습 및 결과
for epoch in range(n_epochs):
time_start = datetime.now()
history_loss = [0, 0]
generator.train()
for photos, sketches, _ in dataloader:
photos = photos.cuda()
sketches = sketches.cuda()
'''
Discriminator
'''
optimizer_D.zero_grad()
# generate sketch
photo_fake = generator(sketches)
# discriminator classify photos
D_real = discriminator(photos, sketches)
D_fake = discriminator(photo_fake, sketches)
# loss
loss_real = loss_gan(D_real, ones)
loss_fake = loss_gan(D_fake, zeros)
loss_D = (loss_real + loss_fake) / 2
history_loss[0] += loss_D.item()
# update D
loss_D.backward()
optimizer_D.step()
'''
Generator
'''
optimizer_G.zero_grad()
# generate image
photo_fake = generator(sketches)
# loss
D_fake = discriminator(photo_fake, photos)
loss_G = loss_gan(D_fake, ones) + lambda_l1 * loss_l1(photos, photo_fake)
history_loss[1] += loss_G.item()
# update G
loss_G.backward()
optimizer_G.step()
'''
History
'''
time_end = datetime.now() - time_start
loss = [history_loss[0]/len(dataloader), history_loss[1]/len(dataloader)]
history['D'].append(loss[0])
history['G'].append(loss[1])
generator.eval()
with torch.no_grad():
history_photo.append(generator(sketch))
print('%2dM %2dS / Epoch %2d / loss_D: %.8f, loss_G: %.8f' %
(*divmod(time_end.seconds, 60), (epoch+1), loss[0], loss[1]))
loss_G의 경우 loss_gan과 loss_l1을 섞어야 하는데 비율은 공식 코드인 phillipi/pix2pix/train.lua를 참고했으며 labmda_l1 값으로는 100을 사용했습니다.
200 epoch 동안 학습하며 생성한 history_photo.
뭔가 열심히 만들고는 있는거 같은데 논문의 결과와는 차이가 있어보입니다… 왜에…..


논문의 figure 14의 일부와 함께 보게 되면 많은 차이가….나네요….. 무언가 잘못됨을 직감합니다. 무엇이 문제일까……어헝헝
4. 수정
학습 결과는 나오지 않고 모델이 문제일까 조금씩 변형해보았지만 큰 차이가 있지 않았습니다. 설마 데이터셋 처리에서 문제가 발생했을거라는 생각을 못하고 애꿎은 모델만 만지다 전체적으로 다시 살펴보다 깨달았습니다ㅎ…..
4.1. 데이터 transform 수정
transform = transforms.Compose([
transforms.Resize((286, 286)),
transforms.RandomCrop((256, 256)), # -> 원인 1
transforms.RandomHorizontalFlip(0.5), # -> 원인 2
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
![]()
transform에서 random jitter와 mirroring을 처리한 게 원인이였습니다. 기껏 페어 이미지 데이터셋을 사용했는데 RandomCrop으로 인해 페어 이미지 간의 crop 위치 차이가 발생하고 RandomHorizontalFlip으로 인해 페어 이미지 둘 중 하나의 이미지만 Flip 된다면 또 페어 이미지 간의 차이가 발생하게 되는 것이 문제로 이어졌습니다.
주로 transform으로만 데이터를 처리하다보니 페어 데이터에서는 이런 문제가 발생할 수 있다는 사실을 생각 못했네요… 코드는 pytorch discuss에서 참고해서 새로 작성했습니다.
class Facade(Dataset):
def __init__(self, path, transform = None):
self.filenames = glob(path + '/*.jpg')
self.transform = transform
def __getitem__(self, idx):
photoname = self.filenames[idx]
sketchname = self.filenames[idx][:-3] + 'png'
photo = Image.open(photoname).convert('RGB')
sketch = Image.open(sketchname).convert('RGB')
if self.transform:
photo = self.transform(photo)
sketch = self.transform(sketch)
# jitter(randomcrop)
i, j, h, w = transforms.RandomCrop.get_params(photo, output_size=(256, 256))
photo = transforms.functional.crop(photo, i, j, h, w)
sketch = transforms.functional.crop(sketch, i, j, h, w)
# flip
if random.random() > 0.5:
photo = transforms.functional.hflip(photo)
sketch = transforms.functional.hflip(sketch)
return photo, sketch, (photoname, sketchname)
def __len__(self):
return len(self.filenames)
transform = transforms.Compose([
transforms.Resize((286, 286)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset_Facade = Facade(path = data_path,
transform=transform)
dataloader = DataLoader(dataset=dataset_Facade,
batch_size=batch_size,
shuffle=True)
새로운 코드로 다시 학습을 시켜봅시다!
4.2. 재학습 결과
야후! 이전보다 좋은 결과를 보여주고 있습니다.
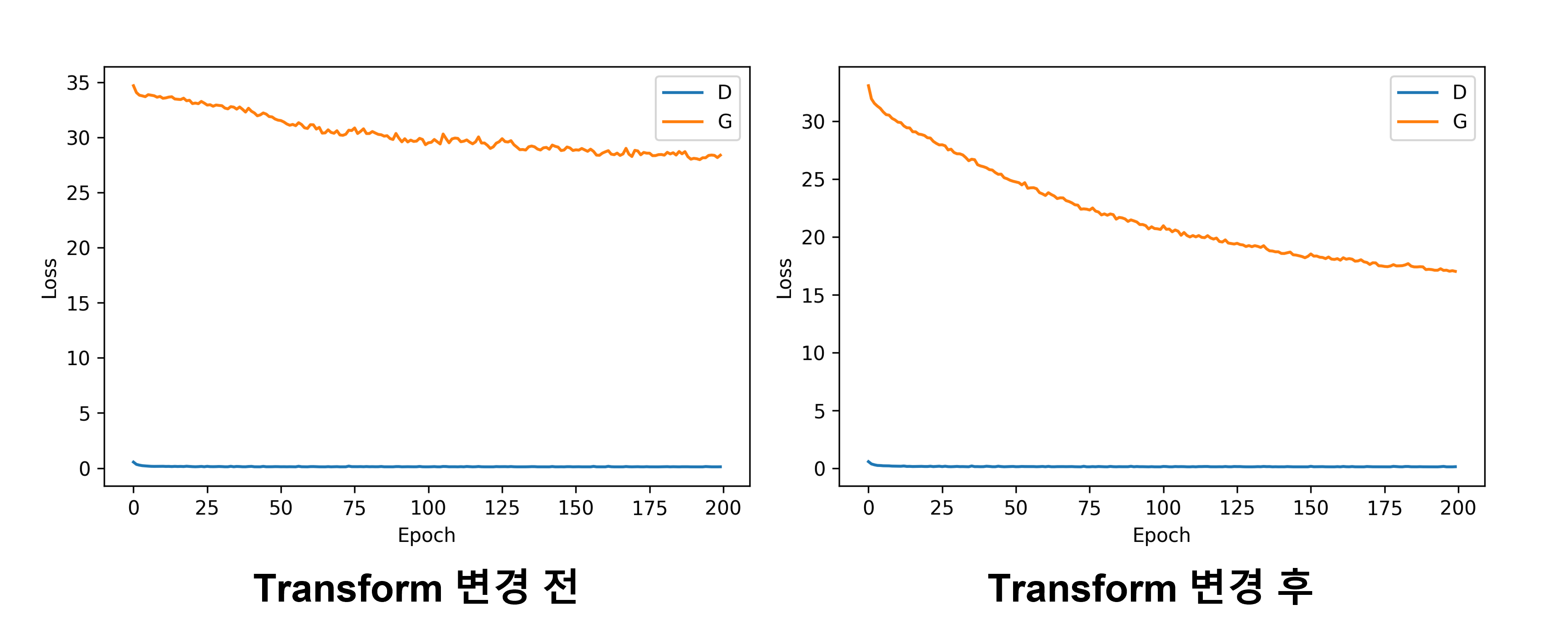
history graph에서도 generator(G)의 loss가 줄어들고 있는 모습을 확인할 수 있었습니다.

추가로 학습하지 않은 데이터 셋인 CMP facade DB extended에서 2장의 라벨링 파일을 학습한 모델로 테스트해보았습니다. 클래스가 다양하고 여러 구조를 가진 이미지로 골랐는데 확실히 학습 데이터셋의 결과에 비하면 상대적으로 퀄리티가 조금 떨어지는 것처럼 보이긴 하지만 386장만으로 이정도 퀄리티가 나온다는 것도 조금 신기하기도 했습니다.
Pix2Pix 글은 여기서 끝입니다! 봐주셔서 감사합니다!!
이번 논문을 구현하면서는 transform에 대한 교훈이 가장 중요했던 것 같습니다…. 문제가 생겼을 때 모델이나 하이퍼 파라미터 종류만 수정하는 것 위주였는데 시간을 날리면서 깨우침을 얻은 기분입니다 ![]()
최종코드는 github에서 확인하실 수 있습니다:)