 solee
solee
MUNIT(1) - 논문 리뷰
이번 논문은 MUNIT(Multimodal Unsupervised Image-to-Image Translation) 입니다. multi-domain을 다뤘던 StarGAN에서 multi-modal을 다루는 MUNIT으로 넘어왔습니다. ![]()
VAE-GAN을 사용하는 것이 특징으로 multi-modal 능력을 확인하기 위해 LPIPS, CIS를 사용해 모델의 성능을 측정해 좋은 성능을 증명했습니다. 모델의 구조부터 결과까지 하나하나 살펴보겠습니다:)
소개
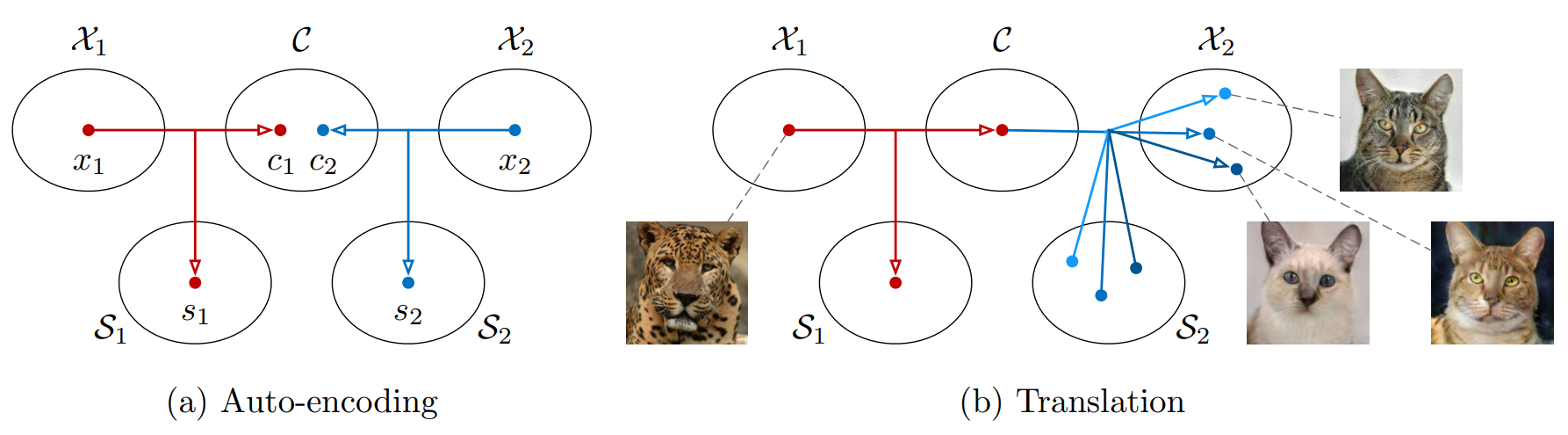
Figure 1. MUNIT 그림 예시.
(a)각 도메인 $\mathcal{X}_i$의 이미지는 공유 콘텐츠 공간 $\mathcal{C}$와 도메인 별 스타일 공간 $\mathcal{S}_i$로 인코딩됩니다.
(b) $\mathcal{X}_1$의 이미지(표범)을 $\mathcal{X}_2$(집 고양이)로 변환하려면 표범 이미지의 콘텐츠 코드를 고양이 도메인의 스타일 공간 내의 임의의 스타일 코드와 재조합합니다. 스타일 코드가 달라지면 출력이 달라져 다양한 고양이 출력이 가능합니다.
비지도 이미지 변환(Unsupervised image-to-image translation)에 다양한 출력을 생성할 수 있는 Multimodal이 가능한 프레임워크인 Multimodal Unsupervised Image-to-image Translation(MUNIT)을 소개합니다. 기존 모델들은 one-to-one 매핑으로 결정론적(deterministic) 출력만이 가능해 하나의 입력 이미지에는 이미지 변환이 된 하나의 출력 이미지가 나왔었습니다. Pix2Pix에서는 결정론적(deterministic)이 아닌 확률론적(stochastic)인 모델을 위해 노이즈를 함께 넣더라도 네트워크는 노이즈를 무시하도록 학습했다고 언급합니다.
이런 문제를 해결하기 위해 MUNIT은 이미지의 잠재 공간(latent space)을 콘텐츠 공간(content space), 스타일 공간(style space)로 분해될 수 있다 가정합니다. 이때 서로 다른 도메인의 이미지가 콘텐츠 공간은 공유하나(shared content space), 스타일 공간은 공유하지 않는다 가정합니다. 이미지에서 보존해야 하는 정보는 콘텐츠 코드(content code)에 인코딩되고, 도메인 별 속성 정보는 스타일 코드(style code)에 인코딩됩니다.
예시로 같은 길거리에 대해서 낮에 찍은 이미지와 밤에 찍은 이미지가 있다면 길거리의 구조, 건물들과 같은 내용은 콘텐츠 코드로 인코딩되고 낮의 밝은 조명, 푸른 하늘 / 밤의 어둑한 조명, 넓게 깔린 그림자와 같은 묘사들은 스타일 코드에 인코딩됩니다. 스타일 공간에서 다양한 스타일 코드를 샘플링할 수 있으며 따라서 MUNIT은 다양한 멀티모달(multi-modal) 출력을 생성할 수 있습니다.
모델
Assumption
MUNIT은 도메인 $\mathcal{X}_1$에서 온 이미지 $x_1$ ($x_1 \in \mathcal{X}_1$)과 도메인 $\mathcal{X}_2$에서 온 이미지 $x_2$ ($x_2 \in \mathcal{X}_2$)를 사용합니다. 이미지 $x_1$을 도메인 $\mathcal{X}_1$에서 도메인 $\mathcal{X}_2$로 변환하는 모델 $p(x _{1 \rightarrow 2} | x_1)$와 이미지 $x_2$을 도메인 $\mathcal{X}_2$에서 도메인 $\mathcal{X}_1$로 변환하는 모델 $p(x _{2 \rightarrow 1} | x_2)$을 사용해 $p(x_1 | x_2)$와 $p(x_2 | x_1)$을 추정하는 것이 MUNIT의 목표입니다.
$p(x_1 | x_2)$, $p(x_2 | x_1)$는 복잡한 multimodal distribution으로 이를 해결하기 위해 부분적으로 공유되는 잠재 공간을 가정합니다. 이미지 $x_i$는 두 도메인에서 공유되는 잠재 콘텐츠 코드(shared content code) $c \in \mathcal{C}$와 각각 도메인에 고유한 잠재 스타일 코드(style code) $s_i \in \mathcal{S}_i$에서 생성된다 가정합니다.
MUNIT은 생성 모델에 콘텐츠 코드와 스타일 코드를 입력해 이미지를 재조합합니다. 이미지 $x_1$은 콘텐츠 코드 $c$와 이미지 $x_1$의 스타일 코드 $s_1$을 사용해 $G ^* _1(c, s_1)$로 만들 수 있으며 이미지 $x_2$는 콘텐츠 코드 $c$와 이미지 $x_2$의 스타일 코드 $s_2$을 사용해 $G ^* _2(c, s_2)$로 생성할 수 있습니다. 여기서 이미지에서 콘텐츠 코드 $c$와 스타일 코드 $s$를 추출하는 것은 Content Encoder와 Style Encoder, 콘텐츠 코드 $c_i$, 스타일 코드 $s_i$를 입력으로 받아 이미지 $x_i$로 만드는 $G$는 Decoder가 됩니다.
Encoder, Decoder는 결정론적(deterministic)이기 때문에 멀티모달 출력을 생성할 수 없습니다. 하지만 Style Encoder로 Style space를 분리하고 Style space에서 continuous하게 스타일 코드를 샘플링해 다양한 style code를 가질 수 있기에 continuous distribution을 가지게 되고 다양한 스타일을 가진 이미지를 생성할 수 있게 됩니다.
Auto-Encoder + GAN
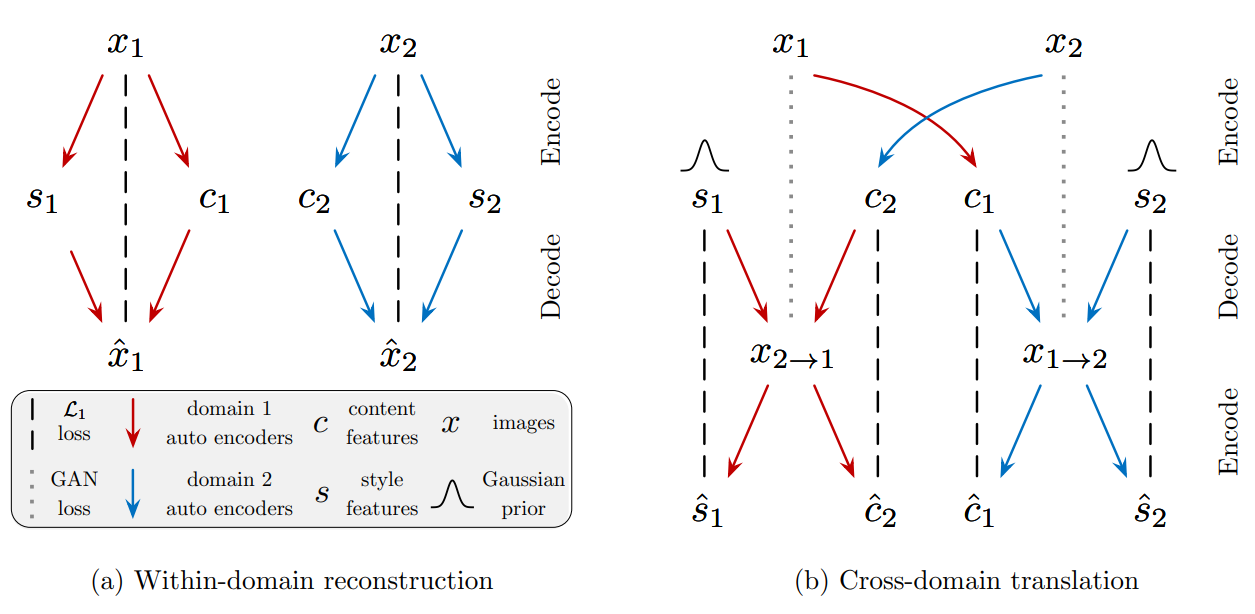
Fig.2 모델 개요.
image-to-image 변환 모델은 각 도메인에 2개의 auto-encoder(빨간색과 파란색 화살표)로 구성됩니다. 각 auto-encoder의 latent code는 콘텐츠 코드 $c$와 스타일 코드 $s$로 구성됩니다.
변환된 이미지가 목표 도메인의 실제 이미지와 구별되지 않도록 adversarial 목적함수(검은색 점선)와 이미지와 잠재 코드 모두를 재구성하는 bidirectional reconstruction 목적함수(회색 점선)을 사용해 모델을 학습합니다.
Fig. 2는 모델의 개요와 학습 과정을 보여줍니다. UNIT과 비슷하게 MUNIT은 도메인 별 encoder $E ^c _i$, encoder $E ^s _i$ decoder $G_i$로 구성됩니다. 도메인 별로 encoder 2개와 decoder 1개가 있으며 encoder 2개는 각각 이미지의 content와 style을 담당합니다. Encode 과정에서 content encoder($E ^c _i$)와 style encoder($E ^s _i$)에 이미지 $x_i$를 입력해 content code $c_i$(content feature)와 style code $s_i$(style feature)를 추출합니다. Decode 과정에서 decoder($G$, generator)는 입력으로 content code와 style code를 입력으로 받아 다시 이미지를 만듭니다.
Fig.2 (a)에서 auto-encoder를 이용해 $(c_i, s_i) = (E ^c _i(x_i), E ^s _i(x_i)) = E_i(x_i)$를 만드는 과정을 보여주며 Content Encoder로 content code $c_i$와 Style Encoder로 style code $s_i$를 분리한 후 다시 생성 모델인 Decoder($G$)로 이미지 $\hat{x}$를 만드는 과정을 확인할 수 있습니다.
Fig.2 (b)에서 image-to-image 변환 과정에 대해 볼 수 있습니다. image-to-image 변환은 encoder-decoder 페어를 교환해 수행됩니다. 이미지 $x_1 \in \mathcal{X_1}$를 $\mathcal{X_2}$에 해당하도록 변환하기 위해 MUNIT은 우선 이미지의 잠재 content code $c_1$을 content encoder로 추출($E^c_1(x_1)$)하고 잠재 style code $s_2$를 prior distribution $q(s_2)\sim \mathcal{N}(0, I)$에서 무작위로 추출합니다. content code $c_1$과 style code $s_2$를 그 후 decoder인 $G_2$를 이용해 최종 결과 이미지 $x_{1 \rightarrow 2} = G_2(c_1, s_2)$를 생성합니다.
Encoder와 Decoder는 모두 deterministic하지만 MUNIT은 하나의 입력 이미지에서 content code와 style code를 추출해 해당 이미지의 content code와 다른 이미지의 style code들을 decoder인 $G$를 통해 합성하며 다양한 이미지 분포를 만들 수 있기에 multi-modal이 될 수 있습니다.
MINUT 모델은 encoder와 decoder가 역방향임을 보장하는 bidirectional reconstruction loss와 변환된 이미지의 분포를 목표 도메인의 이미지 분포와 일치시키는 adversarial loss를 이용해 학습됩니다.
Details
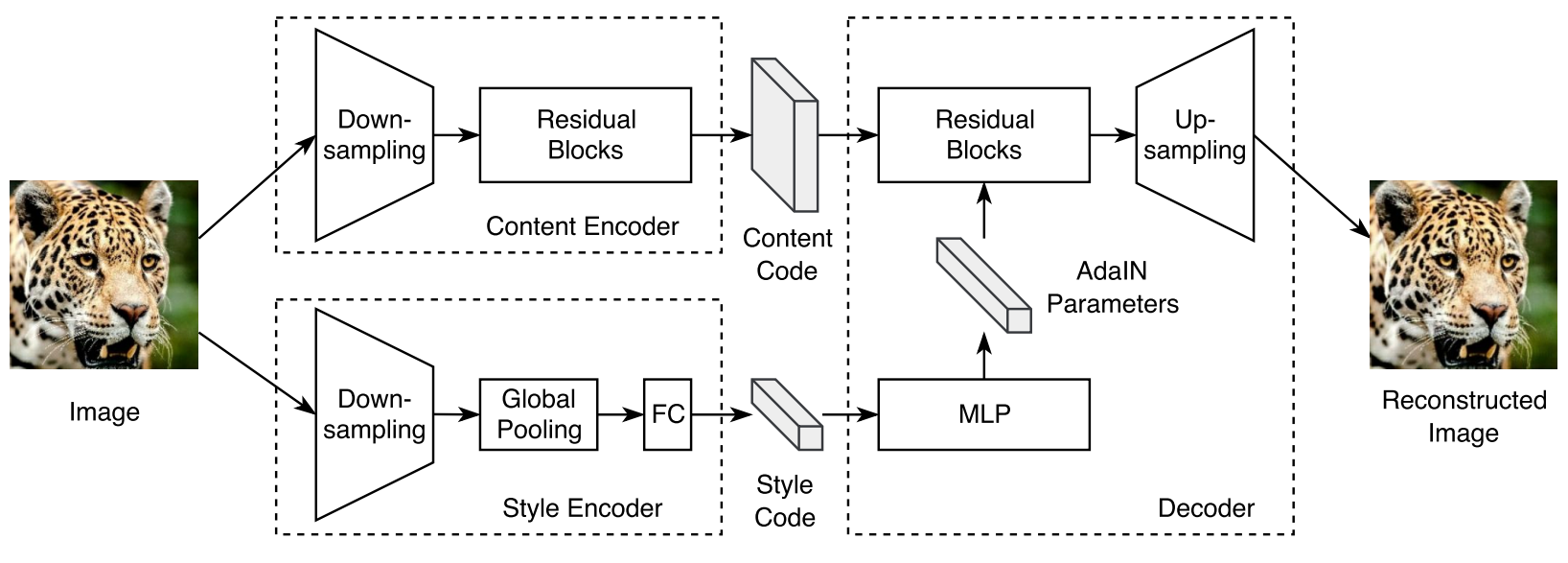
Fig.3 auto-encoder 구조.
Fig.3 에서 auto-encoder의 자세한 구조를 볼 수 있습니다. encoder, decoder, $D$의 하이퍼 파라미터는 논문의 Appendix B에 나와있으며 다음 글인 MUNIT(2) - 코드 구현에서 더 자세하게 설명해드리겠습니다. 여기서는 개략적인 구조를 나눠서 살펴보겠습니다.
-
Content encoder
입력을 down-sampling하기 위해 여러 개의 strided convolutional layer와 ResNet의 residual blocks으로 구성됩니다. -
Style encoder
Content encoder와 마찬가지로 down-sampling을 위해 여러 개의 strided convolutional layer가 포함되어 있습니다. 이후 global average pooling와 fully connected(FC) layer들이 이어집니다. Style encoder에서 Instance Normalization(IN) layer를 쓰지 않는데, AdaIN에 따르면 IN은 중요한 style information을 나타내는 original feature인 mean과 variance를 제거하기 때문입니다. -
Decoder
Decoder로 입력 콘텐츠 코드와 스타일 코드를 이용해 이미지를 재조합합니다. 콘텐츠 코드를 residual block으로 처리하고 스타일 코드를 Multilayer perceptron(MLP)에 의해 파라미터가 동적으로 생성되는 Adaptive Instance Normalization(AdaIN)을 사용해 처리합니다. 최종적으로 여러 up-sampling과 convolutional layer을 통해 재구성된 이미지를 생성합니다. -
Discriminator
LSGAN이 제안한 목적함수를 사용합니다. pix2pixHD이 제안한 multi-scale 판별 모델을 사용해 생성 모델이 사실적인 detail과 올바른 global structure을 생성하도록 유도합니다.
Loss
Bidirectional Reconstruction Loss
서로 역관계인 Encoder와 Decoder를 학습하기 위해 image $\rightarrow$ latent $\rightarrow$ image를 의미하는 Image Reconstruction과 latent $\rightarrow$ image $\rightarrow$ latent를 의미하는 Latent Reconstruction을 모두 사용해 학습합니다.
Image Reconstruction
이미지로 encoder, decoding 단계를 거쳐 이미지를 재구성할 수 있어야 함을 의미합니다.
이미지 $x_1$에서 Content encoder$E ^c _1$와 Style encoder$E ^s _1$로 content code($E ^c _1(x_1)$)와 style code($E ^s _1(x_1)$)을 추출한 후 두 코드를 다시 $G_1$으로 재조합($G_1(E ^c _1(x_1), E ^s _1(x_1))$)한다면 원본 이미지 $x_1$과 차이가 없어야 합니다.
Latent Reconstruction
변환된 이미지에서 encoding 단계를 거쳐 conetent code와 style code를 추출하면 변환된 이미지를 만들 때 $G$에게 입력한 content code와 style code가 나와야 함을 의미합니다.
컨텐츠 코드에 대한 latent Reconstruction 수식입니다. 컨텐츠 코드 $c_1$과 스타일 코드 $s_2$를 이용해 생성 모델로 이미지 $G_2(c_1, s_2)$를 만들고, content encoder $E ^c _2$ 에 이 이미지를 입력으로 준다면 다시 콘텐츠 코드 $c_1$이 나와야 합니다. $E ^c _c(G_2(c_1, s_1))$의 결과와 이상적인 결과값에 해당하는 $c_1$과의 차이를 L1 distance로 계산한 것이 $\mathcal{L} ^{c_1} _{recon}$이 됩니다.
스타일 코드에 대한 latent Reconstruction 수식입니다. 위와 마찬가지로 생성 모델에 입력으로 컨텐츠 코드 $c_1$과 스타일 코드 $s_2$를 입력으로 줘 만든 이미지 $G_2(c_1, s_2)$를 style encoder $E ^s _2$에 입력으로 준다면 이미지를 생성할 때 사용했던 스타일 코드 $s_2$가 나와야 합니다. $E ^s _2 (G_2(c_1, s_2))$의 결과와 이상적인 결과값에 해당하는 $s_2$와의 차이를 L1 distance로 계산한 것이 $\mathcal{L} ^{s_2} _{recon}$이 됩니다.
Adversarial Loss
모델에 의해 생성된 이미지는 목표 도메인의 실제 이미지와 구별할 수 없어야 합니다. decoder $G$와 adversarial하게 학습할 $D$를 도입해 학습합니다.
\[\mathcal{L} ^{x_2} _{GAN} = \mathbb{E} _{c_1 \sim p(c_1), s_2 \sim q(s_2)}[log(1-D_2(G_2(c_1, s_2)))] + \mathbb{E} _{x_2 \sim p(x_2)}[logD_2(x_2)]\]이미지 $x_1$, $x_2$가 있을 때, $x_1$의 콘텐츠에 $x_2$의 스타일을 합성하는 경우 위의 수식으로 adversarial loss를 계산할 수 있습니다. $D_2$는 $\mathcal{X}_2$의 실제 이미지와 변환된 이미지를 구별하는 판별 모델이 됩니다.
반대의 경우인 $\mathcal{L}^{x_1}_{GAN}$에서 판별 모델 $D_1$을 사용한 adversarial loss의 경우에도 유사하게 계산할 수 있습니다.
Total Loss
adversarial loss와 bidirectional reconstruction loss를 모두 사용한 최종 목적 함수는 아래와 같습니다.
\[\displaylines{\min _{E1, E2, G1, G2} \max _{D1, D2} \mathcal{L}(E1, E2, G1, G2, D1, D2) = \mathcal{L} ^{x_1} _{GAN} + \mathcal{L} ^{x_2} _{GAN} + \\ \lambda_x (\mathcal{L} ^{x_1} _{recon} + \mathcal{L} ^{x_2} _{recon}) + \lambda_c (\mathcal{L} ^{c_1} _{recon} + \mathcal{L} ^{c_2} _{recon}) + \lambda_s (\mathcal{L} ^{s_1} _{recon} + \mathcal{L} ^{s_2} _{recon})}\]$\lambda_x$, $\lambda_c$, $\lambda_s$는 reconstruction term의 중요성을 제어하는 가중치로 $\lambda_x=10, \lambda_c=1, \lambda_s=1$을 사용합니다.
Domain-invariant perceptual loss
perceptual loss는 VGG feature map의 거리를 계산한 이미지 간 차이를 loss로 사용하며 pix2pixHD에서 paired supervised 환경의 image-to-image 변환에 도움이 되는 것으로 나타났습니다. 그러나 비지도 설정을 사용하는 MUNIT에서는 사용할 수 없어 논문에서 다른 도메인의 이미지에도 perceptual loss를 적용할 수 있는 Domain-invariant perceptual loss를 제안했습니다.
같은 콘텐츠를 가진 이미지 또는 같은 스타일을 가진 이미지 페어를 사용하며 VGG feature(relu4_3)를 사용해 이미지 사이 거리를 계산합니다. 이후 original feature의 mean, variance를 제거하기 위해 Instance Normalization을 수행해 loss로 사용합니다. 논문에서 domain-invariant perceptual loss는 고해상도(> 512x512) 이미지 데이터에만 적용한다 언급되어 있습니다.
사용 데이터셋
총 4가지 데이터셋을 사용합니다.
-
Edges $\leftrightarrow$ shoes / hangbags
Isola et al. , Yu et al., Zhu et al.이 제공한 데이터셋을 사용합니다. HED에서 생성한 신발과 핸드백의 edge map 이미지가 포함되어 있습니다. 페어 데이터를 사용하지 않고 edges $\leftrightarrow$ shoes와 edges $\leftrightarrow$ handbag에 대해 학습합니다. -
Animal image Translation
ImageNet에서 house cats, big cats, dogs 3가지 도메인의 이미지들을 수집해 얼굴 부분을 crop한 데이터셋을 사용합니다. 각 도메인에는 세분화된 4개의 모드가 포함되며 변환 모델을 학습하는 동안에는 이미지의 모드를 알 수 없습니다. 논문에서는 각 페어 도메인에 대해 별도의 모델을 학습했습니다. -
Street scene images
SYNTHIA 데이터셋 / Cityscape 데이터셋 간 변환과 UNIT의 거리 이미지에서 여름과 겨울 거리 이미지 변환, 총 2가지 변환에 대해 실험했습니다. SYNTHIA 데이터셋의 경우 계절, 날씨, 조명의 조건이 다른 이미지들을 포함하는 SYNTHIA-Seqs 하위 데이터셋을 사용했습니다. -
Yosemite summer $\leftrightarrow$ winter (HD)
UNIT 데이터셋을 사용했으며 실제 주행 영상에서 추출한 여름 및 겨울의 거리 이미지들이 포함되어 있습니다.
평가 지표
Human preference
이전 논문들에서도 등장했었던 Amazon Mechanical Turk(AMT) 연구를 통해 지각 연구를 수행합니다. pix2pixHD의 연구와 유사하게 작업자에게 입력 이미지와 서로 다른 방법으로 변환한 결과 이미지 2개가 주어지며 어떤 결과 이미지가 더 정확해 보이는지 선택할 시간이 무제한으로 주어집니다. 비교를 위해 500개의 무작위 질문을 생성했으며 각 질문에는 5명의 다른 작업자가 답변합니다.
LPIPS distance
변환의 다양성을 측정하기 위해 BicycleGAN과 같이 동일한 입력에서 무작위로 샘플링된 2개의 변환 결과 간의 평균 LPIPS Distance을 계산합니다.
LPIPS는 이미지 간의 차이를 측정하는 방법으로 인간의 시각적 인식과 상관관계가 있는 것으로 입증되었습니다. VGG, AlexNet, SqueezeNet을 이용해 두 이미지의 feature map을 이용해 2개의 feature가 유사한지 측정하는 방식으로 MUNIT 논문에서는 ImageNet으로 학습된 AlexNet을 사용합니다.
\[d(x, x_0) = \Sigma \frac{1}{H_l W_l} \Sigma \| w_l \odot (\hat{y}^l_{hw} - \hat{y}^l_{0hw}) \| _2\]위의 수식이 LPIPS를 계산시 사용하는 수식으로 이미지가 deep feature를 추출하는 모델의 레이어 별 feature map 간의 차이를 L2 distance로 계산함을 의미합니다. $l$은 layer, $H, W$는 각각 Height, Width를 의미하며 $\hat{y}^l_{hw}, \hat{y}^l_{0hw}$은 AlexNet의 $l$ 레이어를 통과했을 때의 feature map을 의미합니다. $w_l$은 scale factor로 두 이미지의 크기가 다른 경우에도 LPIPS Distance를 계산하기 위해 사용합니다. 이미지의 크기가 같다면 1로 두기 때문에 따로 계산할 필요가 없습니다.
(Conditional) Inception Score
Original Inception Score
Inception Score(IS)는 이미지 생성 작업에서 널리 사용되는 지표로 이미지가 사실적인 이미지인지, 이미지가 다양하게 생성되고 있는지를 수치를 이용해 판단할 수 있습니다.
\[IS = \mathrm{exp}(\mathbb{E}_x KL(p(y|x) \| p(y)))\]KL은 Kullback-Leibler divergence(KLD)로 entropy 차이를 비교해 두 확률 분포의 차이를 계산하는 함수입니다. KL로 비교하는 두 확률 분포의 차이가 클수록 IS 점수가 크게 됨을 수식에서 볼 수 있습니다. 여기서 KL이 비교하는 확률 분포인 $p(y)$와 $p(y \vert x)$에 대해서 살펴보겠습니다.
우선 Inception Score는 생성된 이미지를 평가하기 위해 사전 학습된 Inception 판별 모델을 이용해 이미지를 분류한 결과로 점수를 추정합니다. 생성 모델이 생성한 이미지를 $x$, 해당 이미지를 판별 모델에 입력으로 넣었을 때 나온 클래스 라벨이 $y$입니다.
$p(y)$는 판별 모델이 추정한 이미지들의 클래스 분포로 $p(y) = \int p(y \vert x)p_g(x)dx$로 표현할 수 있습니다. 생성 모델이 만든 이미지 $p_g(x)$를 Inception 판별 모델에 입력으로 넣는다면 해당 이미지가 어떤 클래스를 갖는지에 대한 확률 분포 $p(y \vert x)$를 얻을 수 있습니다. $\int p(y \vert x)p_g(x)dx$로 이미지들의 클래스 분포로 추정되는 $p(y)$, 즉 marginal distribution를 얻을 수 있으며 marginal distribution은 모델이 얼마나 다양한 클래스의 이미지 출력 분포를 가지는지 말해줍니다. 높은 entropy를 가져 다양한 클래스의 이미지를 생성하는 것이 이상적입니다.
$p(y \vert x)$는 위에서 언급되었듯 판별 모델이 어떤 클래스를 갖는지에 대한 확률 분포입니다. 예시로 MNIST 데이터셋을 사용했다 가정해보겠습니다. 생성모델이 ‘0’을 의미하는 사실적인 이미지를 잘 생성했다면 판별모델은 이미지가 ‘0’일 확률을 다른 확률에 비해 굉장히 크게 판단해 결과로 ‘0’을 출력합니다. 하지만 생성모델이 ‘0’을 의미하는 사실적인 이미지를 생성하지 못했다면 판별 모델은 이미지가 어떤 숫자인지 판별하기 힘들어 ‘0’일 확률과 다른 숫자의 확률이 크게 다르지 않게 됩니다. 즉, 생성 모델이 사실적인 이미지를 생성할수록 판별 모델이 이미지가 어떤 클래스에 속하는지 판별하기 쉬워져 $p(y \vert x)$가 낮은 entropy를 가지게 됩니다.
이상적인 경우 $p(y)$의 entropy는 높고 $p(y \vert x)$의 entropy는 낮으니 entropy 차이를 비교하는 KL의 결과값은 커지고 IS 값 또한 커지게 됩니다. 따라서 IS 값이 높은 모델일 수록 사실적이고 다양한 결과를 출력했다 할 수 있습니다.
Conditional Inception Score
MUNIT 논문은 멀티모달 이미지 변환에 더 적합한 Conditional Inception Score(CIS)를 제안합니다.
\[CIS = \mathbb{E} _{x_1 \sim p(x_1)}[\mathbb{E} _{x _{1 \rightarrow 2} \sim p(x _{2 \rightarrow 1} | x_1)}[KL(p(y_2|x _{1 \rightarrow 2}) \parallel p(y_2|x_1)]]\]KLD를 이용하는 것은 기존 Inception Score와 큰 차이가 없어보입니다. 하지만 분포에 조건이 추가된 것이 보이니 CIS도 수식을 살펴보겠습니다.
IS에서 $p(y)$였던 것에서 도메인 조건이 붙어 $p(y_2 \vert x_1)$가 되었습니다. $p(y_2 \vert x_1) = \int p(y \vert x _{1 \rightarrow 2})p(x _{1 \rightarrow 2} \vert x_1)dx _{1 \rightarrow 2}$로 표현할 수 있습니다. 도메인 $\mathcal{X}_1$에 속하는 이미지 $x_1$을 도메인 $\mathcal{X}_2$로 변환하는 생성모델에 입력으로 넣어 생성한 이미지 분포 $p(x _{1 \rightarrow 2} | 1)$을 얻습니다. 이후 생성한 이미지 $x _{1 \rightarrow 2}$를 판별 모델에 넣어 이미지가 도메인 $\mathcal{X}_2$의 어떤 모드에 속하는 지에 대한 분포 $p(y \vert x _{1 \rightarrow 2})$를 얻을 수 있습니다. 여기서 모드는 도메인 내의 구별되는 패턴으로 MNIST 도메인이라면 ‘0’ ~ ‘9’까지의 모드가 있는 것이 됩니다. IS와 마찬가지로 $\int p(y \vert x _{1 \rightarrow 2})p(x _{1 \rightarrow 2} \vert x_1)dx _{1 \rightarrow 2}$로 marginal distribution을 얻을 수 있으며 다양한 모드가 출력되는 mode-covering이 되는 것이 이상적입니다. 따라서 $p(y_2 \vert x_1)$은 다양한 출력을 기대하며 높은 entropy를 가져야 합니다.
$p(y_2 \vert x _{1 \rightarrow 2})$는 생성모델에 의해 도메인 $\mathcal{X}_1$에서 도메인 $\mathcal{X}_2$로 변환된 이미지 $x _{1 \rightarrow 2}$를 판별모델에 입력으로 주었을 때 판별모델이 해당 이미지가 도메인 $\mathcal{X}_2$의 어떤 모드에 속하는 지에 대한 확률 분포입니다. IS에서 설명했던 것과 마찬가지로 생성 모델이 사실적인 이미지로 생성을 잘 했다면 특정 모드의 확률 값이 다른 모드보다 크게 되고 판별 모델은 해당 모드로 결과값을 출력합니다. 따라서 $p(y_2 \vert x _{1 \rightarrow 2})$는 낮은 entropy를 가져 판별 모델이 판별하기 쉬워야 합니다.
$p(y_2 \vert x_1)$는 모델이 다양한 모드의 이미지를 출력한다면 높은 entropy를 가지고 $p(y_2 \vert x _{1 \rightarrow 2})$는 모델이 사실적인 이미지를 출력한다면 entropy가 낮으니, 모델이 다양한 모드의 사실적인 이미지를 출력할 수록 KLD의 계산 결과 값은 커지고 CIS 또한 값이 커지게 됩니다. 따라서 CIS 또한 IS와 마찬가지로 값이 높을 수록 모델의 성능이 좋음을 의미합니다.
논문에서는 CIS 뿐만 아니라 IS 또한 사용하는데, 조건이 없는 IS를 계산하기 위해 $p(y_2 \vert x_1)$은 unconditional class probability $p(y_2) = \int\int p(y \vert x_{1 \rightarrow 2})p(x_{1 \rightarrow 2} \vert x_1)p(x_1)dx_1 dx_{1 \rightarrow 2}$로 교체됩니다.
높은 CIS/IS 점수를 얻으려면 모델이 고품질의 다양한 샘플을 생성해야 합니다. IS는 모든 출력 이미지의 다양성을 측정하는 반면, CIS는 단일 입력 이미지에 조건이 지정된 출력의 다양성을 측정합니다. 입력 이미지가 주어졌을 때 결정론적으로 단일 출력을 생성하는 모델은 CIS 점수로 0을 받지만 IS에서는 여전히 높은 점수를 받을 수 있습니다. 논문에서는 특정 데이터셋에 맞게 fine-tunig된 Inception-V3를 판별 모델로 사용하며 100개의 입력 이미지와 입력당 100개의 샘플을 사용해 CIS과 IS를 추정합니다.
결과
Baseline 모델
MUNIT과 비교하기 위한 Baseline 모델로 UNIT, CycleGAN, CycleGAN with noise, BicycleGAN을 사용합니다.
-
UNIT
MUNIT과 유사하게 VAE-GAN으로 구성되나 완전히 공유되는 잠재 공간을 사용한다는 가정이 차이점입니다. Gaussian Encoder와 VAE의 dropout layer에서 stochastic을 이끌어 냅니다. -
CycleGAN
Adversarial loss와 Cycle Reconstruction loss를 사용해 학습한 2개의 residual translation 네트워크입니다. pix2pix가 제안한 것처럼 train, test 모두에서 dropout을 사용해 다양성(diversity)을 만들어 냅니다. -
CycleGAN with noise
CycleGAN 프레임워크로 멀티모달 출력을 생성하기 위해 두 변환 모델에 noise vector를 사용합니다. residual 구조에서는 noise vector를 무시하도록 학습되므로 BicycleGAN처럼 입력에 노이즈를 추가한 U-Net 구조를 사용합니다. CycleGAN과 마찬가지로 train, test 모두에서 dropout을 사용합니다. -
BicycleGAN
MUNIT 논문이 나왔던 시기에 유일하게 image-to-image 변환 모델 중 멀티모달 및 continuous 출력 분포를 생성할 수 있는 모델이였습니다. 하지만 학습 데이터셋으로 페어 데이터셋이 필요하다는 한계를 가지고 있습니다. 따라서 결과 비교시 데이터셋이 페어 데이터셋인 경우에만 MUNIT과 BicycleGAN을 비교합니다.
edges $\leftrightarrow$ shoes/handbags
위의 4가지 Baseline과 MUNIT 모델에서 $\mathcal{L}^x _{recon}$, $\mathcal{L}^c _{recon}$, $\mathcal{L}^s _{recon}$를 각각 제거한 MUNIT의 변형과 MUNIT의 결과를 비교합니다.

Fig.4 edges $\rightarrow$ shoes에 대한 질적 비교. 첫번째 열은 입력 이미지와 정답 이미지입니다. 이후 열들은 해당 방법에서 3가지 무작위 결과를 보여줍니다.
UNIT과 CycleGAN(노이즈 O/ 노이즈 X)은 모두 무작위성을 주입했음에도 불구하고 다양한 출력을 생성하지 못합니다. $\mathcal{L} ^x _{recon}$, $\mathcal{L} ^c _{recon}$가 없는 경우 MUNIT의 이미지 품질이 만족스럽지 못합니다. $\mathcal{L} ^s _{recon}$이 없는 경우 partial mode collapse로 인해 많은 출력이 거의 동일합니다(예시. 첫 2행). MUNIT 모델이 생성한 이미지는 다양하고 사실적으로 BicycleGAN과 유사하지만 지도학습이 필요하지 않습니다.
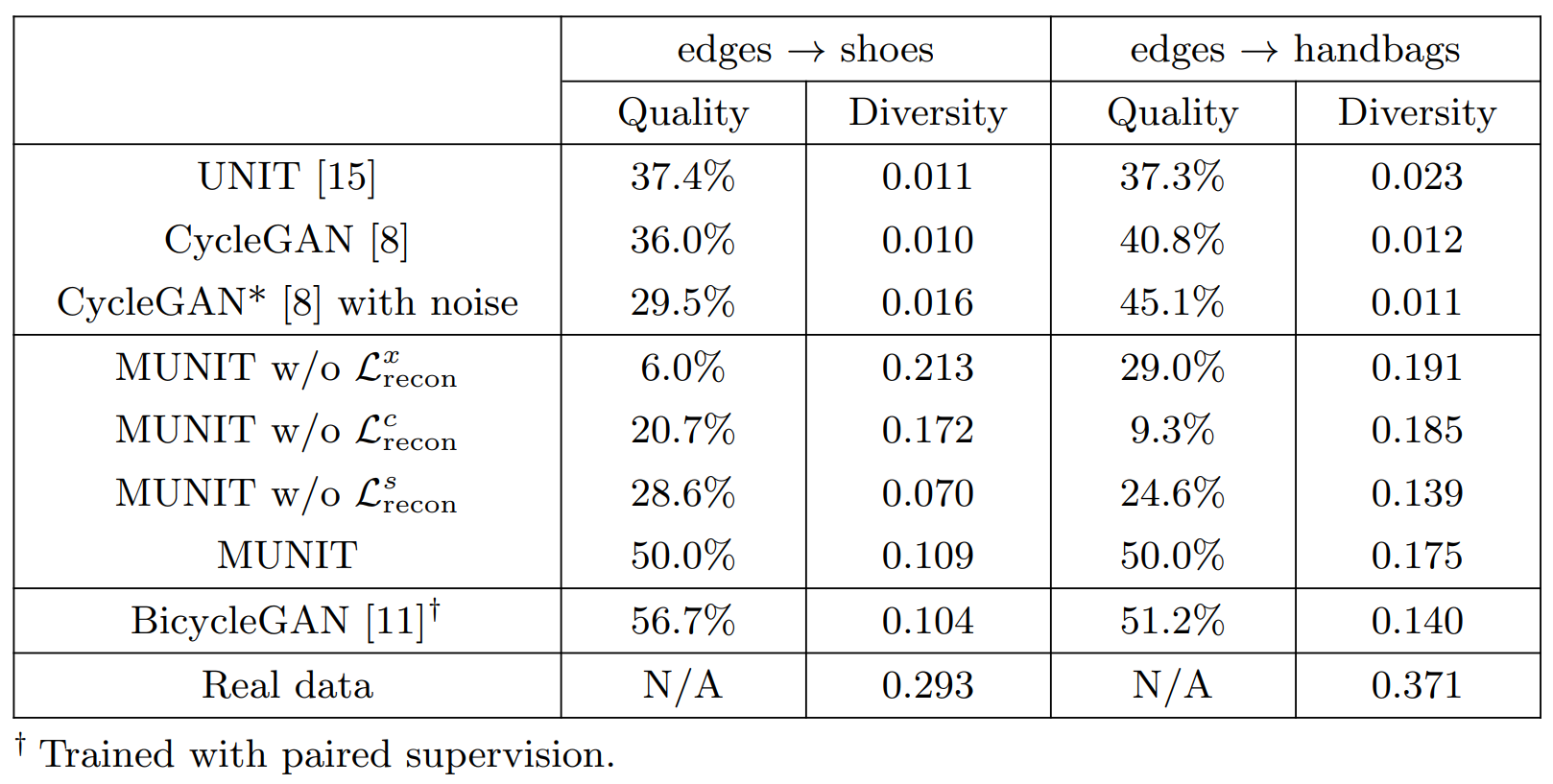
Table.1 edges $\rightarrow$ shoes/handbags에 대한 질적 평가. Diversity 점수는 LPIPS distance의 평균 값입니다. Quality 점수는 사람이 평가한 점수로 MUNIT보다 선호도가 높은 정도를 의미합니다. 두 메트릭 모두 더 높은 값이 좋은 것을 의미합니다.
Section 5.2에 설명된 대로 다양성을 평가하기 위해 human preference(AMT)를 이용해 품질과 LPIPS distance를 측정합니다. 우리는 edges → shoes/handbags 과제에 대해 이 실험을 수행합니다. Table 1에서 볼 수 있듯이 UNIT과 CycleGAN은 LPIPS 거리에 따라 다양성이 매우 적습니다. MUNIT에서 $\mathcal{L}^c_{recon}$을 제거하면 quality 점수가 크게 저하됩니다. $\mathcal{L}^s_{recon}$이 없으면 quality와 diversity 모두 저하됩니다. 전체 모델은 지도학습된 BicycleGAN에 필적하는 quality, diversity 점수를 얻었으며, 모든 비지도 학습 baseline 모델보다 훨씬 우수합니다.

Fig.5 (a) edges $\leftrightarrow$ shoes와 (b) edges $\leftrightarrow$ handbags에 대한 결과들
edges $\leftrightarrow$ shoes/handbags에 대한 MUNIT의 결과를 Fig.5를 통해 확인할 수 있습니다.
animal translation

Fig.6 동물 이미지 변환의 결과
Fig. 6에서 볼 수 있듯이, MUNIT은 한 종류의 동물을 다른 종류로 성공적으로 변환했습니다. 입력 이미지가 주어지면, 변환 출력은 여러 모드, 즉 대상 영역의 여러 세분화된 동물 카테고리를 포괄합니다. 동물의 외형은 크게 변화되었지만 포즈는 전체적으로 유지됩니다.
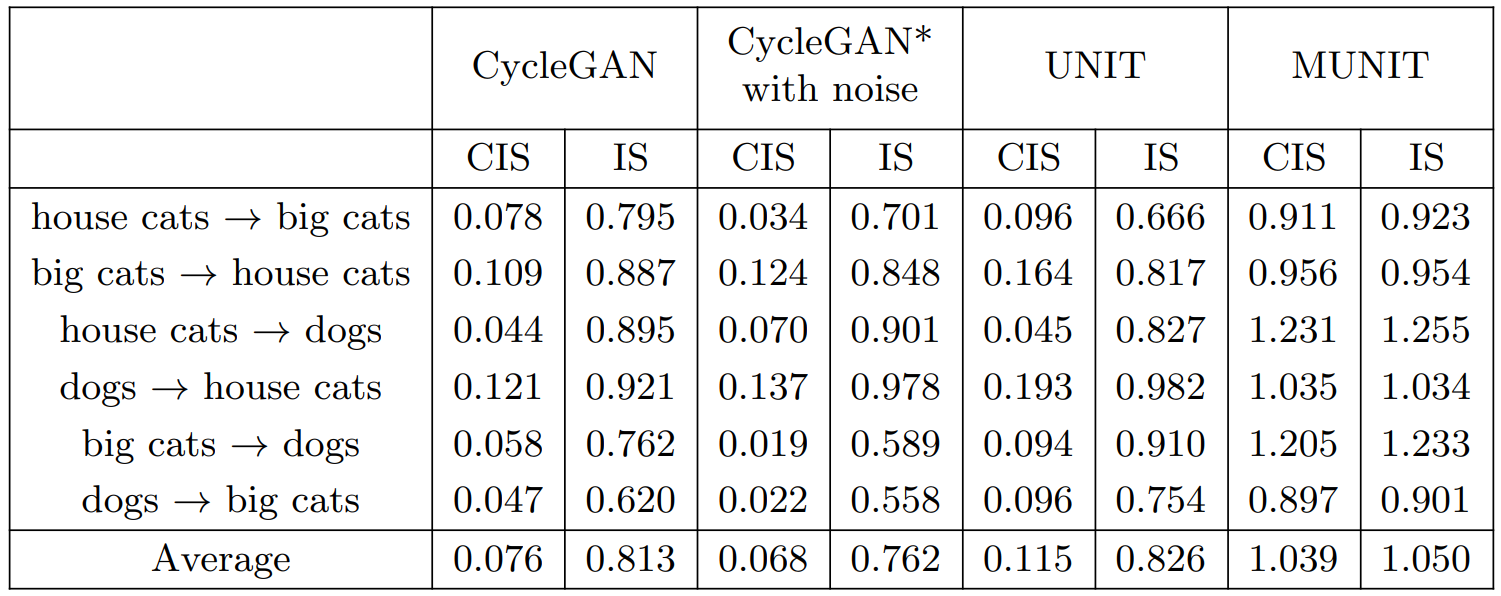
Table.2 동물 이미지 변환에 대한 질적 평가.
house cats, big cats, dogs, 3가지 도메인을 사용했으며 각 도메인 페어에 대해 양방향 변환을 수행해 6가지 변환 실험을 진행했습니다.
Table.2에서 볼 수 있듯 CIS/IS를 사용해 각 모델의 성능을 측정합니다. 높은 CIS/IS 점수를 얻으려면 모델이 고품질과 다양성을 모두 갖춘 샘플을 생성해야 합니다. IS는 모든 출력 이미지의 다양성을 측정하는 반면, CIS는 단일 입력 이미지를 조건으로 한 출력의 다양성을 측정합니다.
MUNIT은 CIS와 IS 모두에서 가장 높은 점수를 얻었습니다. 특히 baseline 모델들은 모두 매우 낮은 CIS를 획득했으며 주어진 입력에서 멀티모달 출력을 생성하지 못함을 나타냈습니다. IS는 이미지 품질과 상관 관계가 있는 것으로 나타났기 때문에, MUNIT의 IS가 높을수록 baseline 방식보다 높은 품질의 이미지를 생성한다는 것을 의미합니다.
Cityscape $\leftrightarrow$ SYNTHIA

Fig.7 거리 장면 변환의 결과
Fig. 7은 거리 장면 데이터셋의 결과를 보여줍니다. 우리의 모델은 주어진 Cityscape 이미지에서 다양한 렌더링(예. 비오는 날, 눈 오는 날, 밝은 날)에 해당하는 SYNTHIA 이미지들을 생성할 수 있으며, 주어진 SYNTHIA 이미지에서 다른 조명, 그림자, 도로 텍스쳐를 가진 Cityscape 이미지들을 생성할 수 있습니다.
Yosemite summer $\leftrightarrow$ winter

Fig.8 Yosemite summer $\leftrightarrow$ winter의 결과(HD 해상도)
Fig. 8은 고해상도 Yosemite 데이터셋에서 summer ↔ winter 변환의 예제 결과를 보여줍니다. 우리의 알고리즘은 조명이 다른 출력 이미지를 생성합니다.
MUNIT 논문 리뷰는 여기서 끝입니다! 다음 글은 MUNIT 코드 구현 글이 되겠네요.
긴 글 끝까지 봐주셔서 감사합니다. 코드 구현에서 뵙겠습니다 ![]()