 solee
solee
Condtional GAN
0. 소개
‘Conditional Generative Adversarial Nets’는 GAN 논문이 발표된 이후 GAN 모델의 단점 중 하나였던 ‘원하는 모드의 결과 추출’을 해결한 논문으로 cGan으로도 불립니다. condition으로 원하는 결과에 해당하는 라벨 값을 주어 원하는 이미지를 생성하는 아이디어로 간단하지만 효과적인 방법이라 생각합니다.
논문에서는 2가지 실험을 진행했는데 첫번째는 기존 GAN 논문에서 실험했던 것과 같은 MNIST 데이터셋을 사용해 원하는 숫자 이미지를 생성하는 것이고 두번째는 Flickr 25k 데이터 셋을 이용한 이미지 태그 생성입니다.
이미지 생성 부분은 이전글이였던 gan 코드를 이용해 cgan을 구현을 설명드리고 이미지 태그 생성 부분은 논문 내용을 소개하고자 합나다.
1. 모델
사실 gan과의 차이는 단 하나입니다. label 값이 주어지는 것 외에는 차이가 없습니다.
cgan의 loss 함수의 식은 아래와 같습니다.
기존 gan의 식에서 $y$ 조건이 추가되어 있습니다.
gan이 $G$에게 노이즈 $z$를 입력으로 주어 $D$를 속일 숫자 이미지를 만드는 것이였다면 cgan은 $G$에게 노이즈 $z$와 라벨 $y$를 입력으로 주어 $y$에 해당하는 숫자 이미지를 만드는 것이 됩니다.
$D$도 마찬가지로 $y$ 조건이 추가됩니다.
gan이 $D$에게 이미지 $x$를 주어 이미지가 $G$가 생성한 이미지인지 아닌지를 판별하는 것이였다면 cgan은 $D$에게 이미지 $x$와 라벨 $y$를 입력으로 주어 이미지가 $G$가 생성한 $y$에 해당하는 이미지인지 판별하는 것이 됩니다.
MNIST 데이터셋에서는 이미지와 이미지에 해당하는 라벨이 있습니다. y 값으로 라벨을 가져오게 되는데 y를 모델에 전달하는데 전달하는 방법은 다양합니다. 단순하게 라벨 숫자를 넘겨주는 방법, one-hot vector로 넘겨주는 방법, Embedding해 넘겨주는 방법 등 원하는 방식으로 처리할 수 있습니다. 저는 one-hot vector로 처리해 모델에 라벨 값을 전달했습니다.
1.1. Generator
기존 코드에서 2가지가 변경되었습니다. 첫번째는 forward 함수에 labels입니다. labels 변수에는 이미지의 라벨 값이 2, 5, 0, …과 같이 10진수로 들어옵니다. 이를 one-hot vector로 변경하기 위해 nn_functional.one_hot() 함수를 이용했습니다. num_classes는 지정하지 않은 경우 labels에 있는 가장 큰 수에 맞춰집니다. batch 단위로 넘어온 labels의 가장 큰 값이 9라는 보장이 없으니 값을 넣어주어야 합니다. one-hot vector로 만든 labels를 기존 노이즈 z에 합쳐 model로 보내줍니다.
두번째 차이점은 model의 첫번째 Linear입니다. 모델에 z를 보내줄 때 one-hot vector를 붙였으니 그 크기만큼 Linear의 in_feature 크기를 늘려주어야 합니다. 따라서 z_dim에 n_classes를 더한 값은 in_feature 크기로 설정했습니다. 그 외에는 기존 gan의 코드와 같습니다.
class Generator(nn.Module):
def __init__(self, z_dim=100, img_shape=(28,28), n_classes=10):
super(Generator, self).__init__()
self.z_dim = z_dim
self.img_shape=img_shape
self.n_classes = n_classes
self.model = nn.Sequential(
nn.Linear(self.z_dim + self.n_classes, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 784),
nn.Sigmoid()
)
def forward(self, z, labels):
labels = nn.functional.one_hot(labels, num_classes=self.n_classes)
z = torch.cat((z, labels), 1)
img = self.model(z)
img = img.view(img.size(0), *self.img_shape)
return img
1.2. Discriminator
Discriminator도 Generator와 마찬가지로 forward 함수의 one-hot vector 부분과 model의 첫번째 Linear의 in_feature 값이 같은 이유로 변경되었습니다.
class Discriminator(nn.Module):
def __init__(self, img_shape=28*28, n_classes=10):
super(Discriminator, self).__init__()
self.n_classes = n_classes
self.model = nn.Sequential(
nn.Linear(img_shape + n_classes, 512),
Maxout(),
nn.Linear(512, 256),
Maxout(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img, labels):
labels = nn.functional.one_hot(labels, num_classes=self.n_classes)
img = torch.cat((img, labels), 1)
output = self.model(img)
return output
2. 학습 결과
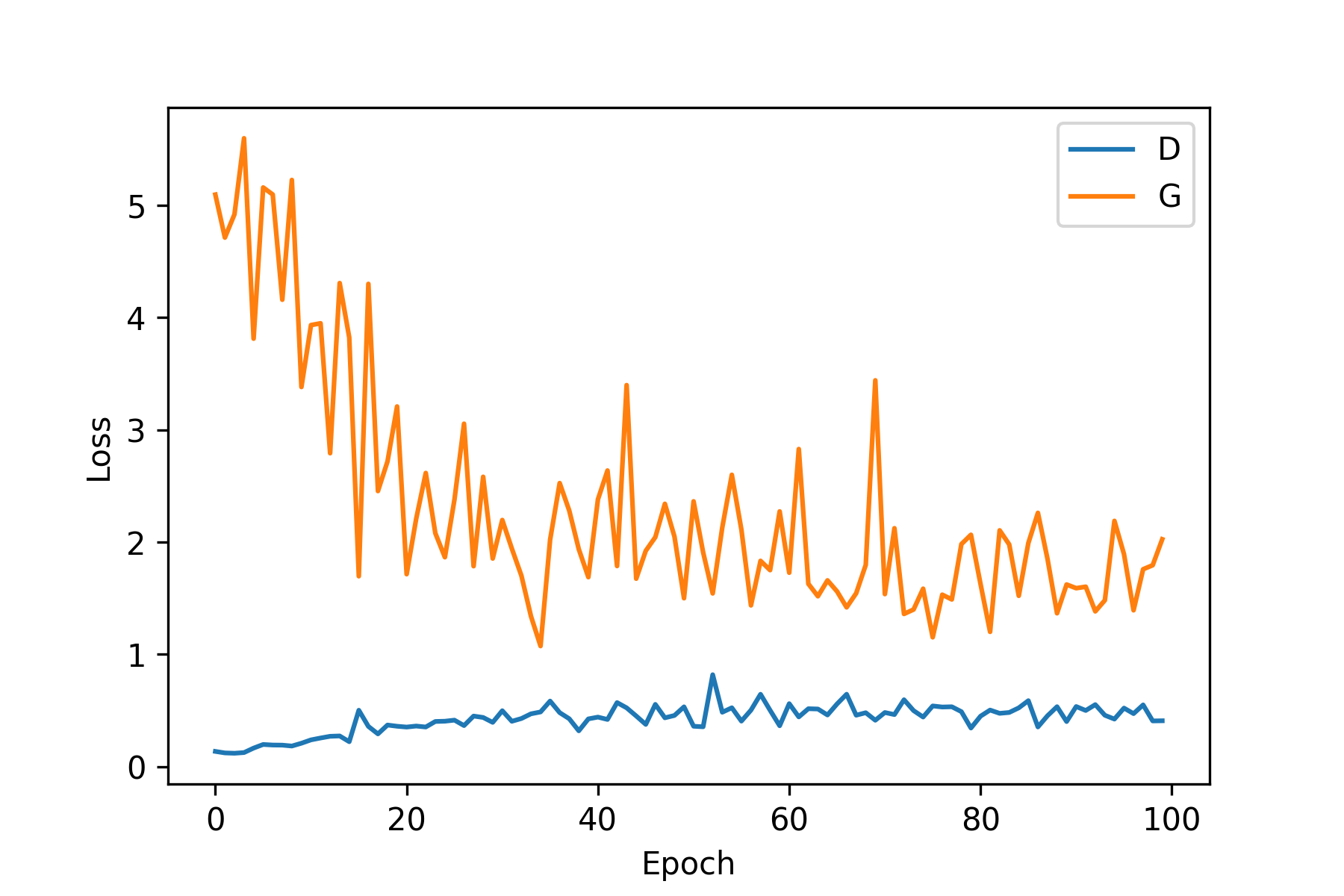
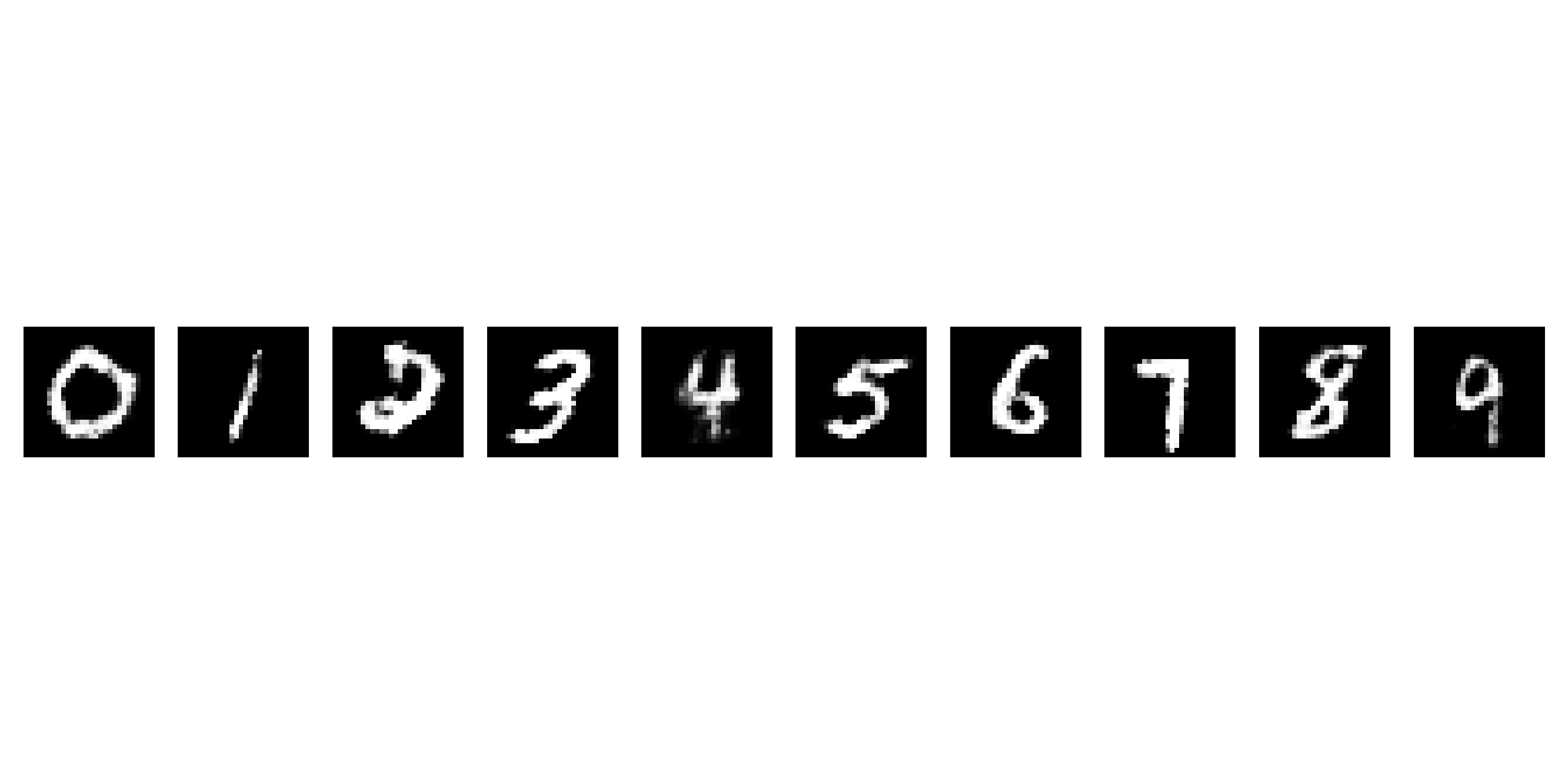
학습 그래프와 학습이 끝난 이후 랜덤 노이즈를 입력으로 받은 $G$가 생성한 결과 이미지입니다. GAN에 비하면 $G$의 학습이 불안정한 모습이라고 생각됩니다. 특정 숫자에 취약할 수 있으니 더 안정화할 수 있는 방법으로 라벨 별 loss를 구해 weight를 차별해서 주는 방법이 있을 수 있겠다는 생각이 들었습니다.
영상은 sample 노이즈를 학습 전 생성해둔 후 $G$가 한번 학습할 때마다 sample 노이즈를 주었을 때 0 ~ 9까지 생성한 결과입니다. sample 노이즈와 라벨 생성은 아래의 코드를 이용했습니다.
sample_img = torch.zeros(10, z_dim)
sample_img += (0.1**0.5)*torch.randn(10, z_dim)
sample_img = sample_img.cuda()
sample_label = torch.arange(0, 10)
sample_label = sample_label.cuda()
전체 코드는 github에서 확인하실 수 있습니다:)
3. 태그 생성
논문에서는 cgan은 2가지 task 수행이 가능하며 MNIST 이미지 생성을 Unimodal, 태그 생성을 Multimodal task로 소개하고 있습니다. Multimodal은 성격이 다른 여러 데이터를 활용한 것으로 본 논문의 경우 자연어와 이미지가 됩니다. 이미지 데이터를 입력으로 받아 이미지를 설명하는 대표 태그 결과를 자연어로 출력하기 때문입니다.
학습 데이터셋으로는 이미지의 경우 ImageNet, 자연어의 경우 YFCC100M을 사용했습니다. YFCC100M은 이미지, 비디오의 데이터가 있으며 각 데이터 별 태그 데이터가 포함된 메타데이터가 포함되어 있습니다. 태그와 설명 데이터를 말뭉치(corpus)로 수집하여 단어 벡터 크기가 200인 skip-gram 모델로 학습했으며 200번 이하로 등장하는 단어를 제외해 총 247465 크기의 단어 사전(dictionary)을 사용했다 합니다.
테스트 데이터셋으로는 MIR Flickr 25,000을 사용했는데 Flickr의 이미지들에 사용자들이 이미지를 설명하는 태그를 달아놓은 데이터셋입니다. 태그가 없는 이미지의 경우 실험에서 제외되었으며 주석이 달려있는 경우 추가 태그로 처리했다고 합니다.
이미지의 태그를 추출하기 위해 한 이미지에서 100개의 태그 샘플을 생성합니다. 태그 샘플 별 가장 가까운 20개의 단어를 cosine similarity를 사용해 단어 사전에서 추출합니다. 마지막으로 가장 많이 등장한 10개의 단어를 찾아내어 태그 결과로 출력합니다.
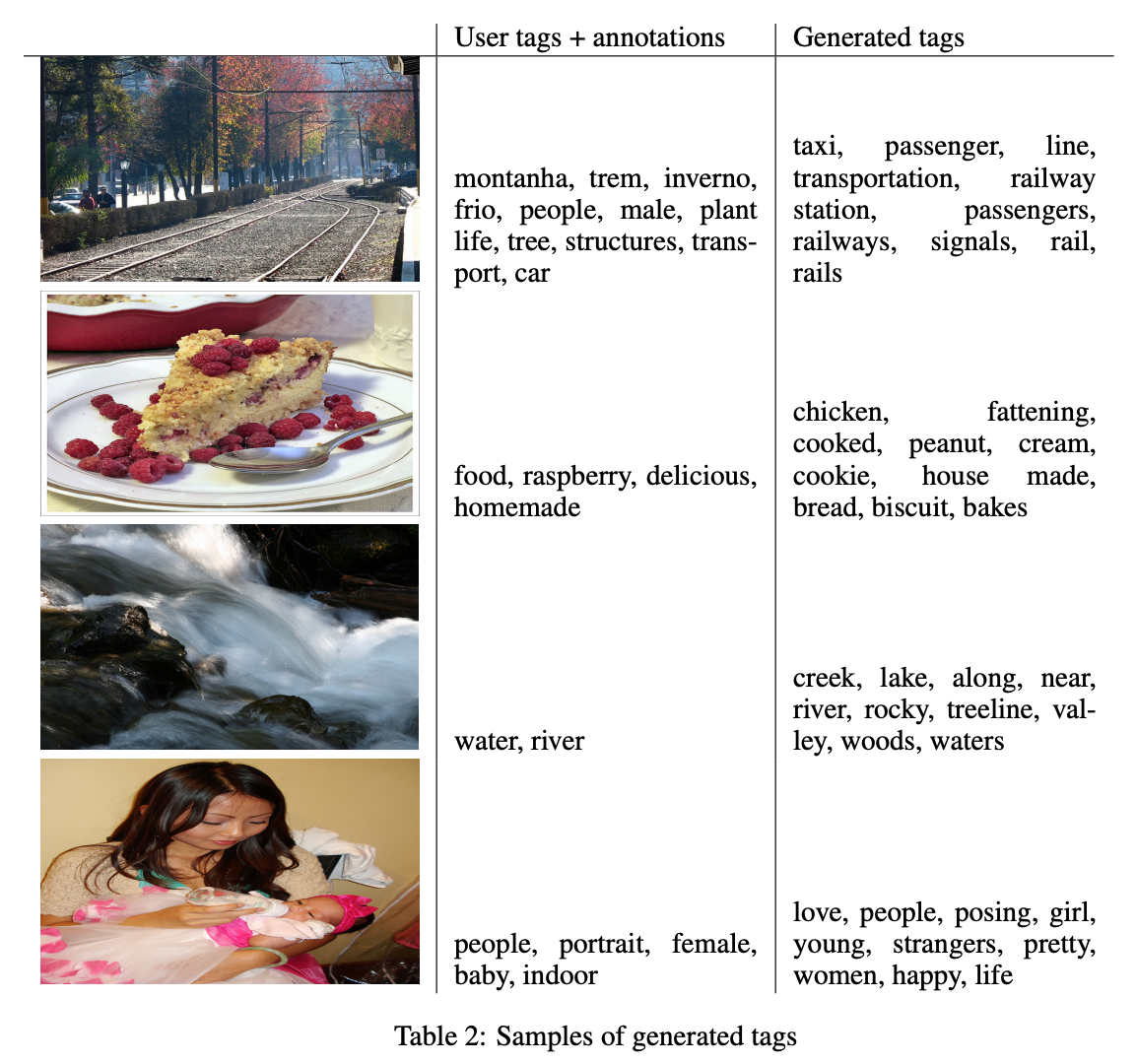
Flickr의 사용자 태그와 모델의 태그 생성 결과를 나타 이미지입니다. Flickr의 이미지 당 평균 태그의 수는 8.94개이며 모델의 경우 10개의 고정된 태그를 생성하다 보니 모델 생성 태그의 수가 더 많은 것을 확인할 수 있습니다.
논문 소개는 여기서 끝입니다:) 끝까지 봐주셔서 감사합니다![]()
저는 이전의 gan 구현 코드에서 간단하게 $y$ 조건을 추가로 주는 방법을 선택했습니다. 만약 논문을 그대로 구현하실 분들은 제 코드가 아니라 논문에 나온 수치를 보신 후 구현하셔야 합니다.
gan의 경우 units의 수나 $z$의 차원 수 같은 설정 값이 나와있지 않았지만 cgan의 경우 굉장히 자세하게 논문에 소개되어 있습니다. mini batch의 크기, decay factor와 learning rate 변화 값 같은 hyper parameter와 maxout의 $k$에 해당하는 pieces 수와 Fuuly connected layer의 units에 해당하는 모델의 구조까지 상세하게 나와있습니다. 모델 구현을 시도하시는 분들은 본 논문의 수치를 확인해주세요!